L10: Message Passing Interface (MPI)
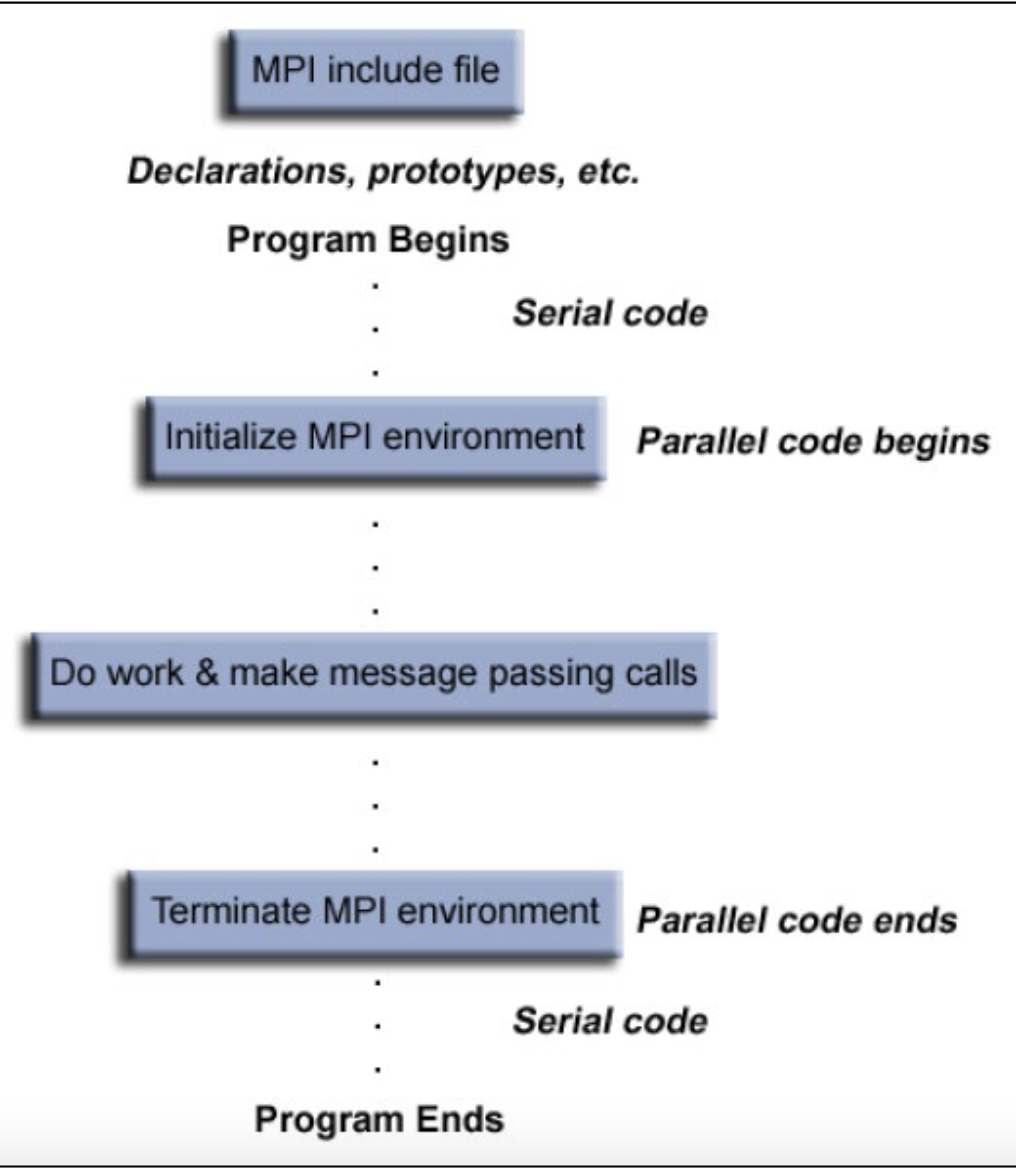
MPI Program Structure
int MPI_Init(int\* argc, char** argv[])
- Initialize the MPI program
- Must be called only once and before any other MPI routines
int MPI_Finalize(void)
- Terminate all MPI processing
- Must be the last MPI call
int MPI_Abort(MPI_Comm comm, int errorCode)
- Force all processes to terminate
- Return the errorcode to mpirun
MPI_Comm_size(MPI_COMM_WORLD, &size);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
Point-to-point Communication
Blocking:
MPI_Send,MPI_RecvMPI_Sendrecv,MPI_Sendrecv_replace
Non-blocking:
MPI_Isend,MPI_Irecv- Blocking and non-blocking operations can be mixed
- Data sent by
MPI_Isend()can be received byMPI_Recv() - Data sent by
MPI_Send()can be received byMPI_Irecv()
- Data sent by
MPI Message Format
Message = data (actual data that you want to send/receive) + envelope (how to route the data)
Data = start-buffer (address where data starts) + count (number of elements of data in the message) + datatype (type of data to be transmitted) +
Envelope = destination or source (using rank in a communicator) + tag (an arbitrary number to distinguish among messages) + communicator (send/receive must specified the same communicator)
MPI Send and Receive
1int MPI_Send(void* buf, int count, MPI_Datatype dt,2 int dest, int tag, MPI_Comm c);3
4int MPI_Recv(void* buf, int count, MPI_Datatype dt,5 int src, int tag, MPI_Comm c, MPI_Status *status);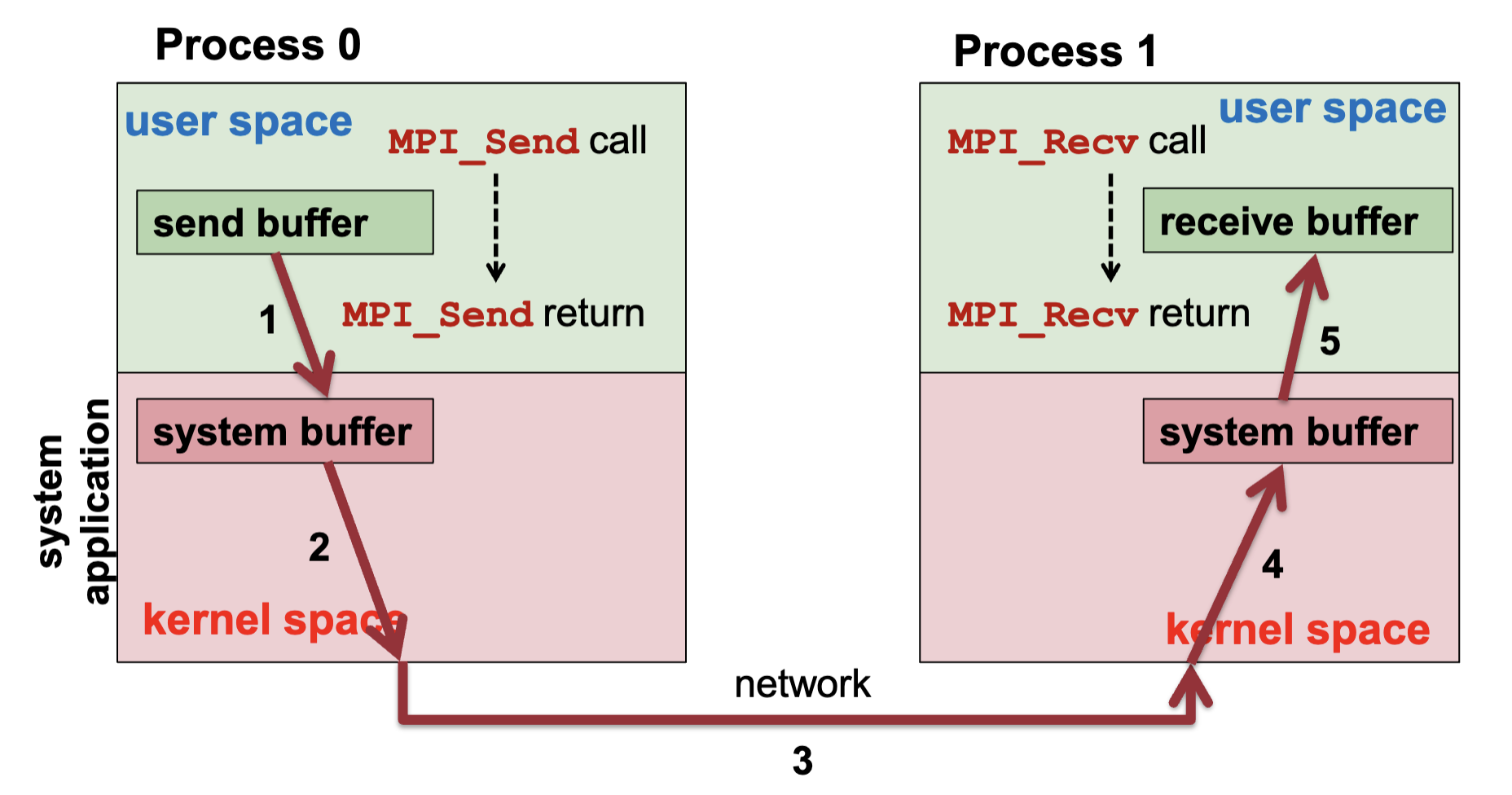
MPI Program Structure
- Received message must be less than or equal to the length of the receive buffer
- For receiving message, use:
src = MPI_ANY_SOURCE→ from any processtag = MPI_ANY_TAG→ message with any tag
MPI_Statusis a structure withMPI_SOURCE,MPI_TAG, andMPI_ERROR
| Synchronous | Asynchronous | |
|---|---|---|
| Blocking | MPI_SSend, (MPI_Mrecv), MPI_RSend | May be buffered: MPI_Send, MPI_Recv; Buffered: MPI_Bsend |
| Non-Blocking | MPI_ISSend, (MPI_ImRecv) | MPI_ISend, MPI_Irecv |
Order of Receive Operations:
- 2 processes (one sender, one receiver): A sender sends two or more messages to the same receiver, messages delivered in the order in which they have been sent
- If more than 2 processes: Message delivery order not guaranteed!
Deadlocks in MPI
- Message Order: Deadlock occurs when message passing cannot be completed
- Process 0 waits for process 1 and vice versa → always deadlock!
- System Buffer: Deadlock occurs if the runtime system does not use system buffers or if the system buffers used are too small
- No system buffer / buffer too small → deadlock (because both sends cannot complete)
Process Groups and Communicators
Process Group:
- An ordered set of processes, each process has a unique rank
- A process may be a member of multiple groups, and may have different ranks in each of these groups
- MPI system handles the representation and management of process groups
Communicator:
- Communicator is the communication domain for a group of processes
- Intra-communicators: Support the execution of arbitrary collective communication operations on a single group
- Default:
MPI_COMM_WORLD
- Default:
- Inter-communicators: Support the point-to-point communication operations between two process groups
Rationale:
- Allow us to organize tasks, based on functions, into task groups
- Enable collective communication operations across a subset of related tasks
- Provide the basis for user-defined virtual topologies
- Provide for safe communication
Operations on Process Group:
-
Obtain a new group:
MPI_Comm_group -
Get size of a group:
MPI_Group_size -
Rank a process in a group:
MPI_Group_rank -
Group union:
MPI_Group_union -
Group intersection:
MPI_Group_intersection -
Group difference:
MPI_Group_difference -
Group inclusion:
MPI_Group_incl -
Group exclusion:
MPI_Group_excl -
Group compare:
MPI_Group_compare -
Delete group:
MPI_Group_free
Operations on Communicators:
-
Get size of communicator:
MPI_Comm_size -
Get rank of process in communicator:
MPI_Comm_rank -
Create communicator:
MPI_Comm_create -
Compare communicators:
MPI_Comm_comp -
Duplicate communicator:
MPI_Comm_dupl -
Split communicator:
MPI_Comm_split -
Delete communicator:
MPI_Comm_free
Process Virtual Topologies
- Sometimes it is useful to have an alternative representation and access e.g. processes communicating with neighbor processes only in a mesh pattern
- Create topologies where neighbors are easily addressable
Virtual Topology Operations:
- Virtual topology: a communicator with a Cartesian style of addressing the ranks of the processes
- Create a Cartesian topology:
MPI_Cart_create - Get info on Cartesian topology:
MPI_Cart_get - Get number of dimension:
MPI_Cartdim_get - Comm rank → Cartesian coords:
MPI_Cart_coords - Cartesian coords → Comm rank:
MPI_Cart_rank - Access neighbors in Cartesian coords:
MPI_Cart_shift
Collective Communication
- Operations that involve all processes in a communicator
- Otherwise: deadlock
- Blocking operations by default
- Two types of operations:
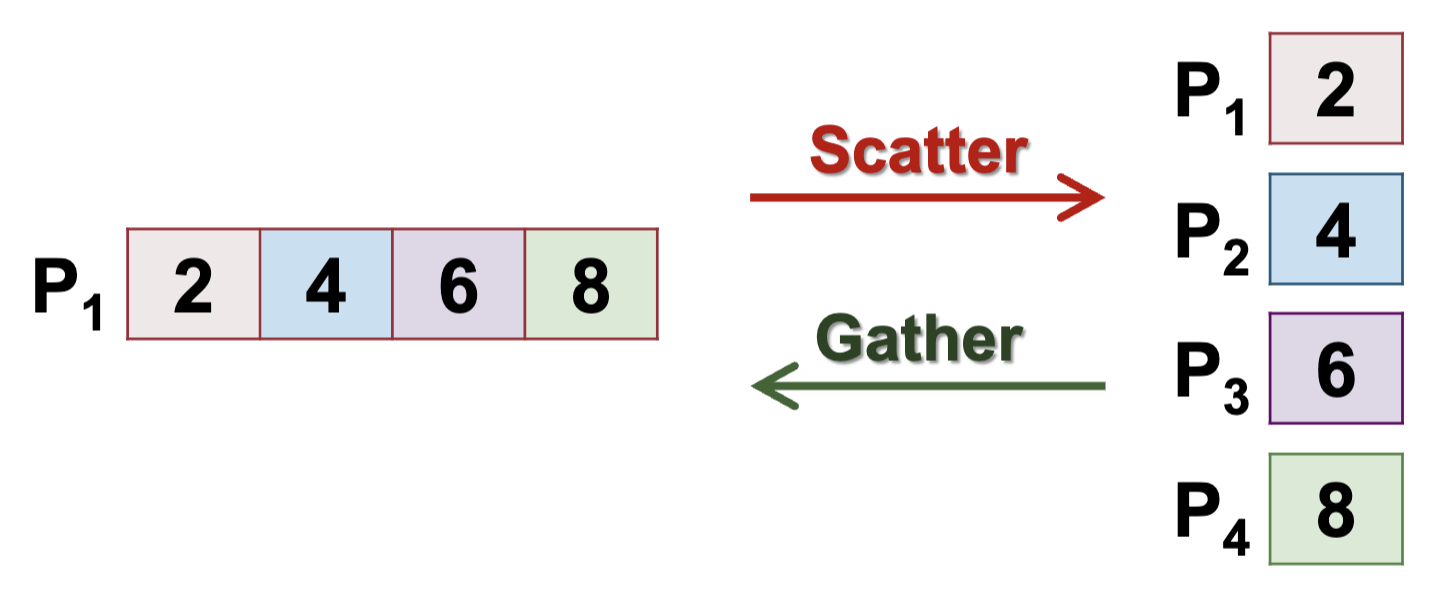
- Scatter: from 1 process to many processes
- Gather: from many processes to 1 process
- With accumulation (reduction) using an arithmetic operation OR Without accumulation
Barrier
Processes block until all processes of the communicator reach the barrier
1int MPI_Barrier(MPI_Comm comm);Measuring Program Timings
- Measure the parallel execution time. Return the absolute time elapsed between the start and the end of a program part
1double MPI_Wtime (void)- Get resolution of
MPI_Wtime()
1double MPI_Wtick (void)Communication Operations
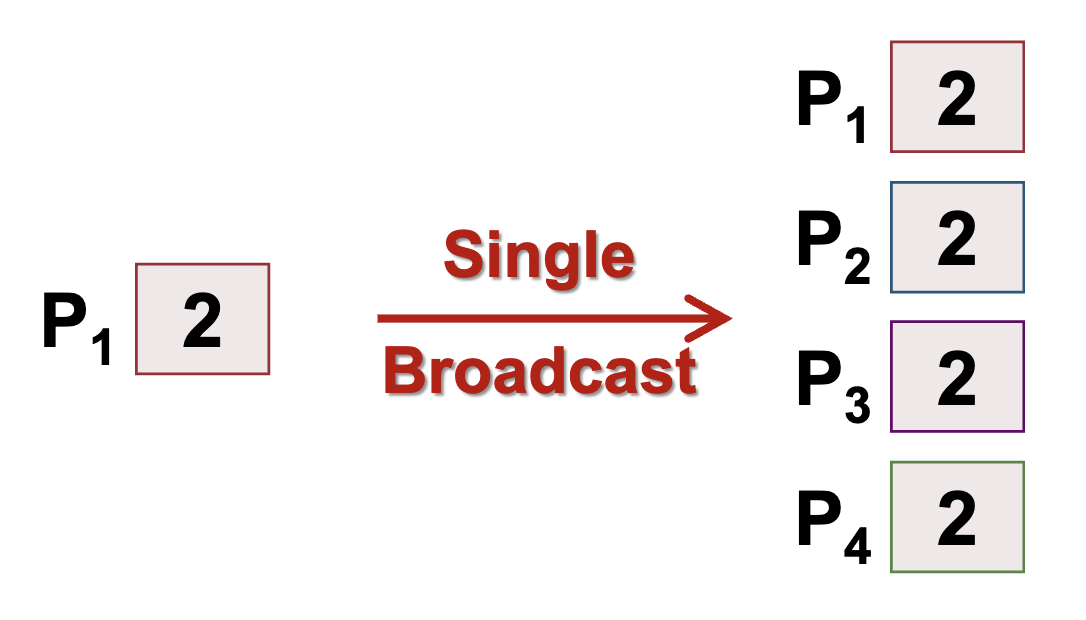
Single Broadcast
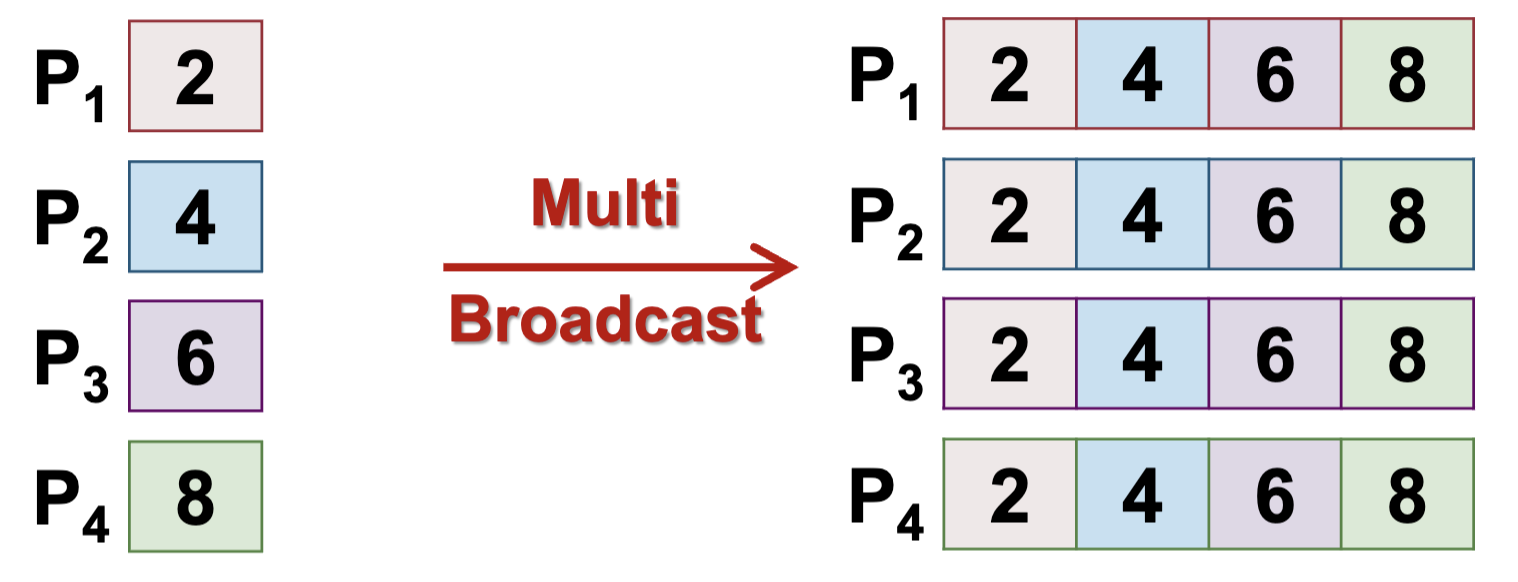
Multi Broadcast - No root processor
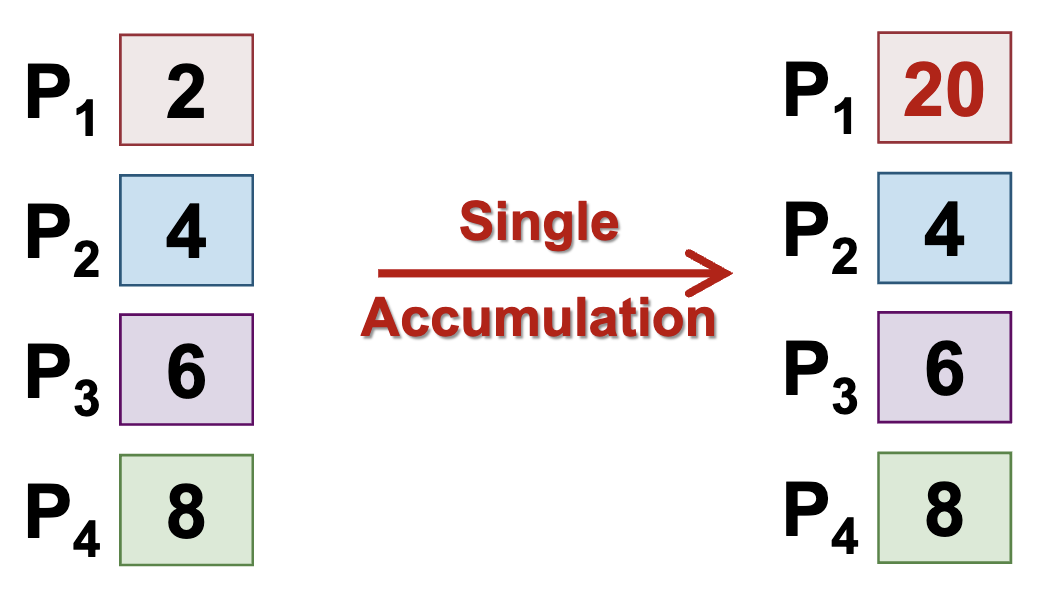
Single Accumulation (Gather with Reduction) - Data of the same type and same size
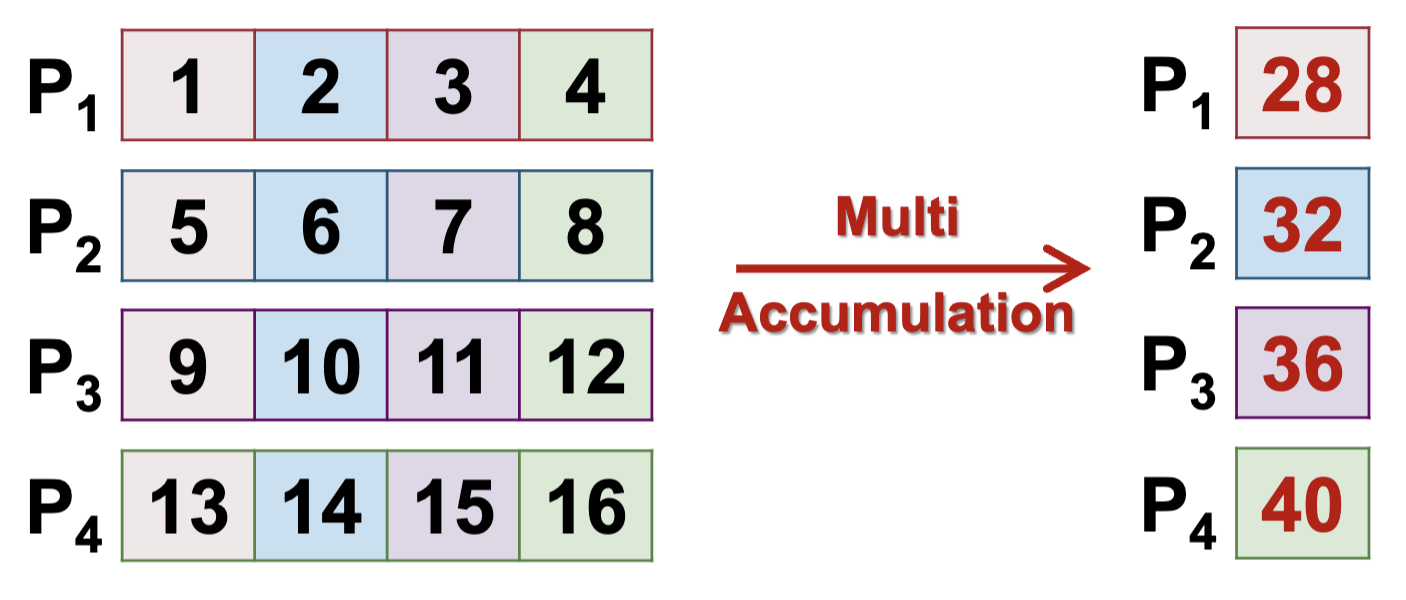
Multi Accumulation - No root process
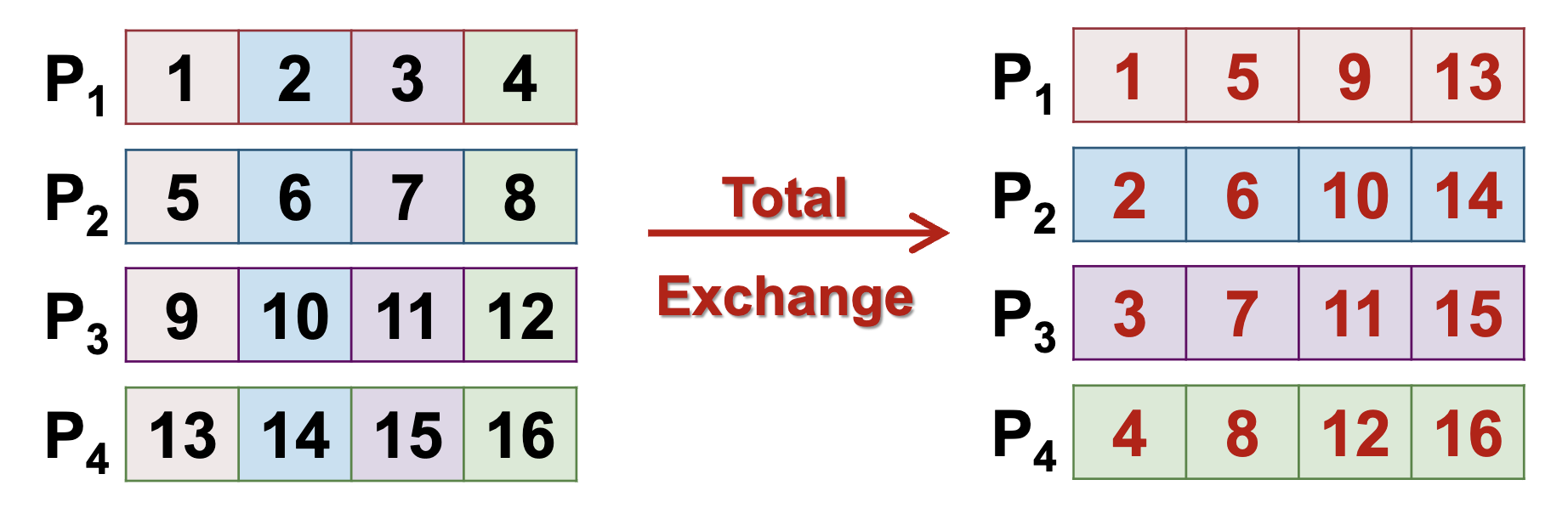
Total Exchange - No root process
Duality of Communication Operations:
- A communication operation can be presented by a graph
- Two communication operations are a duality if the same spanning tree can be used for both operations
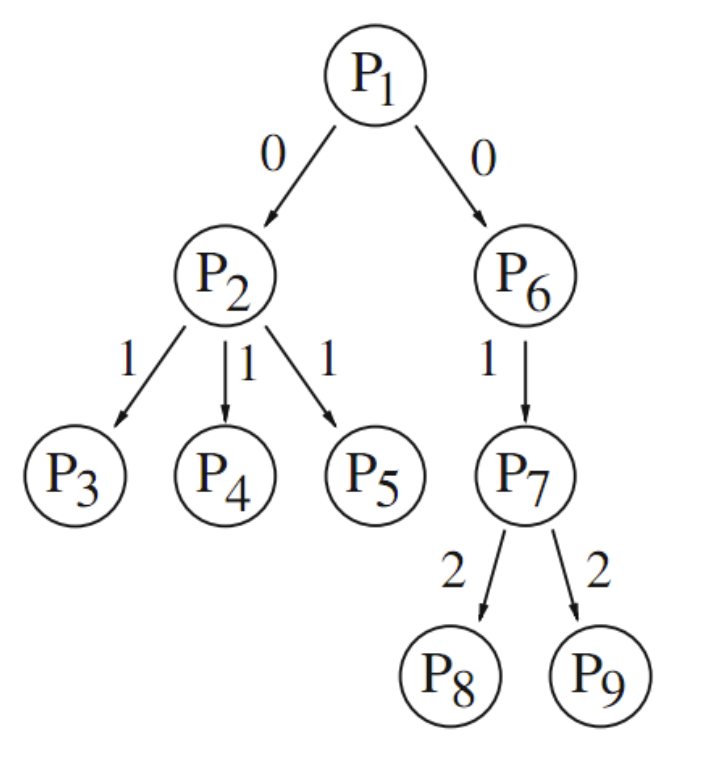
Single-broadcast operation (top-down traversal)
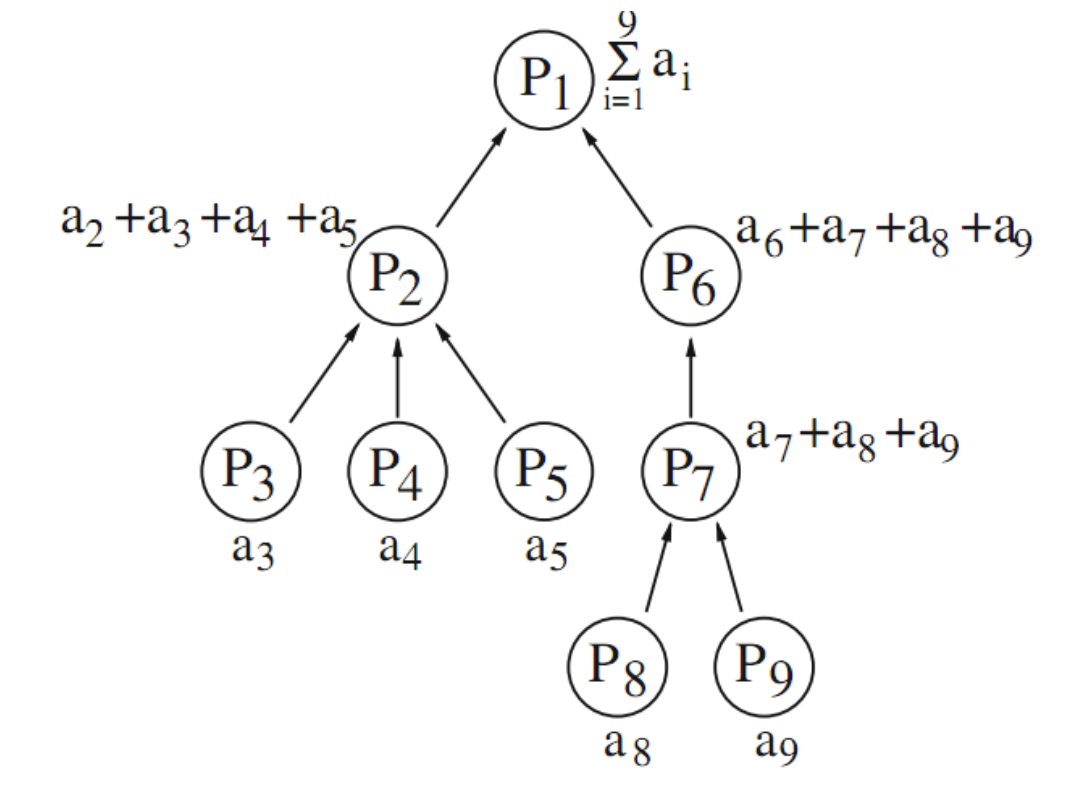
Single-accumulation operation (bottom-up traversal)
Stepwise Specialization:
- Communication operations can be ordered into a hierarchy:
- From the most general to the most specific
- Operations that are resulted from stepwise specialization are placed near to each other
- Example: A stepwise specialization from total exchange to multi-broadcast
- total exchange: each processor sends a different message to each other processor
- multi-broadcast: each processor sends the same message to each other
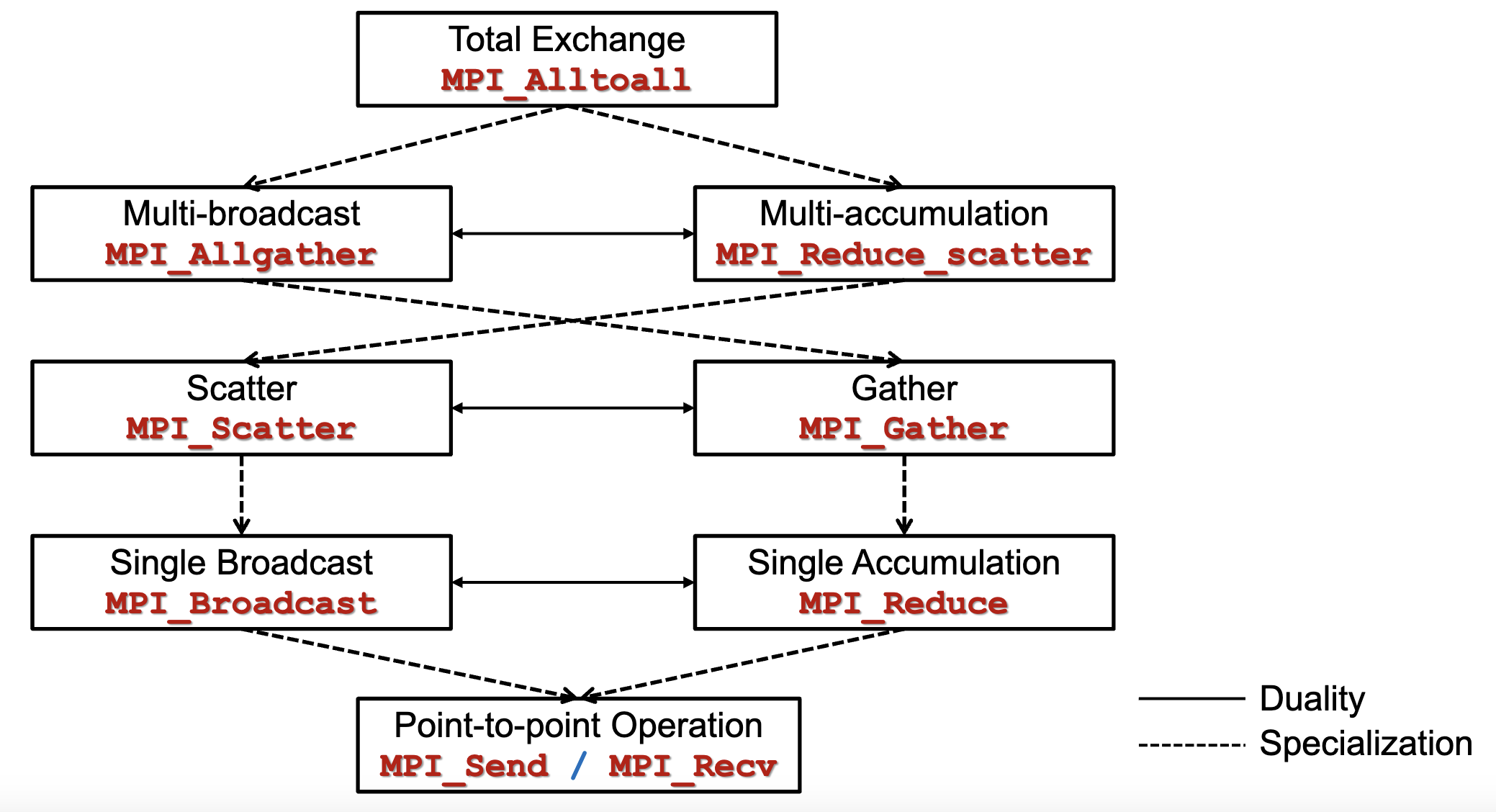
Duality and Specialization