L3: Parallel Computing Architectures
Source of Processor Performance Gain
Bit Level Parallelism
Word size may mean: (16/32/64 bits)
- Unit of transfer between processor memory
- Memory address space capacity
- Integer size
- Single precision floating point number size
Instruction Level Parallelism
Pipelining:
- Split instruction execution in multiple stages, e.g. Fetch (IF), Decode (ID), Execute (EX), Write-Back (WB)
- Allow multiple instructions to occupy different stages in the same clock cycle
- Provided there is no data / control dependencies
- Number of pipeline stages == Maximum achievable speedup
- Disadvantages: Independence, Bubbles, Hazards: data and control flow
Superscalar: Duplicate the pipelines:
- Allow multiple instructions to pass through the same stage
- Scheduling is challenging (decide which instructions can be executed together):
- Dynamic (Hardware decision)
- Static (Compiler decision)
- Disadvantages: structural hazard, data/control dependencies
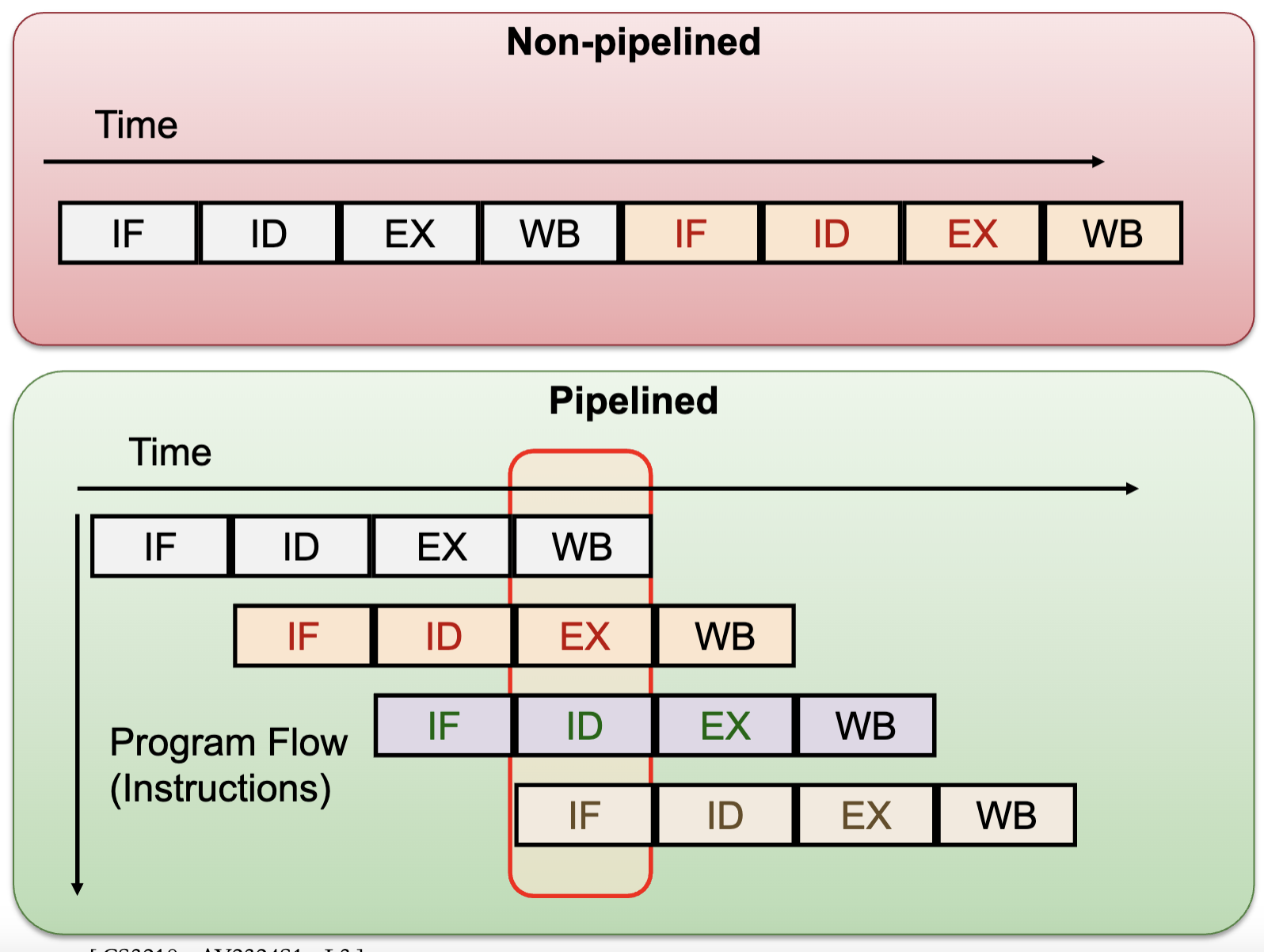
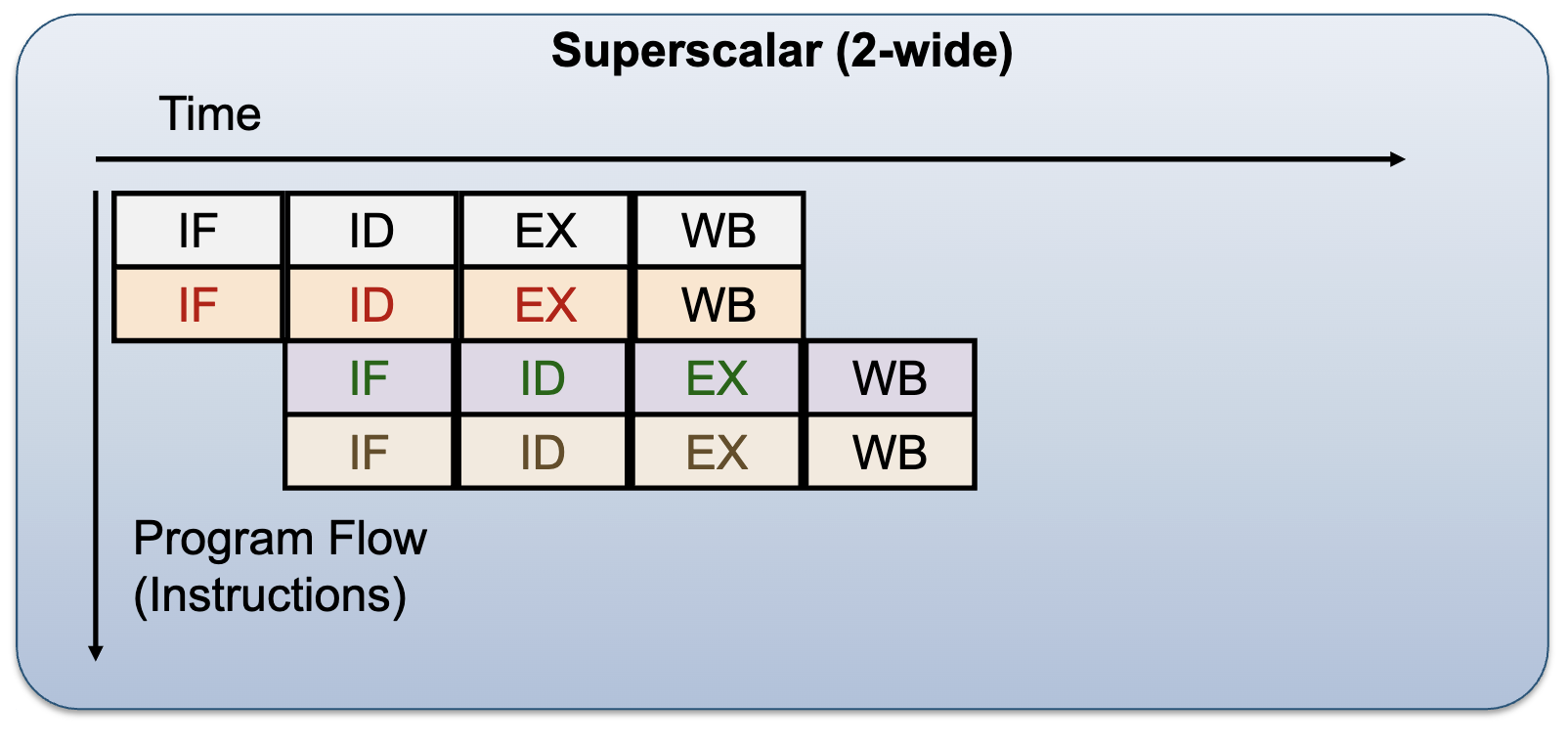
Pipelined vs Superscalar Processor:
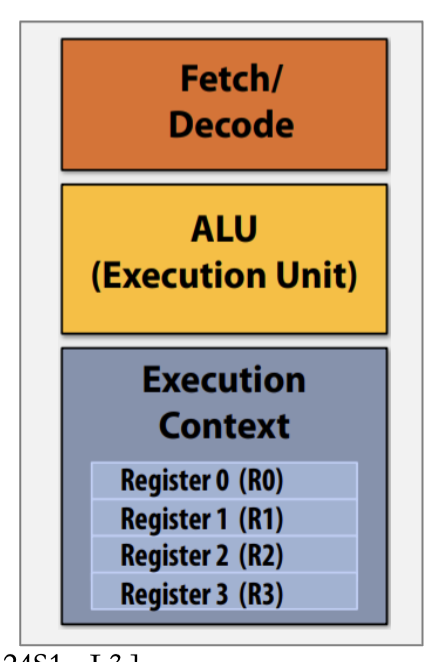
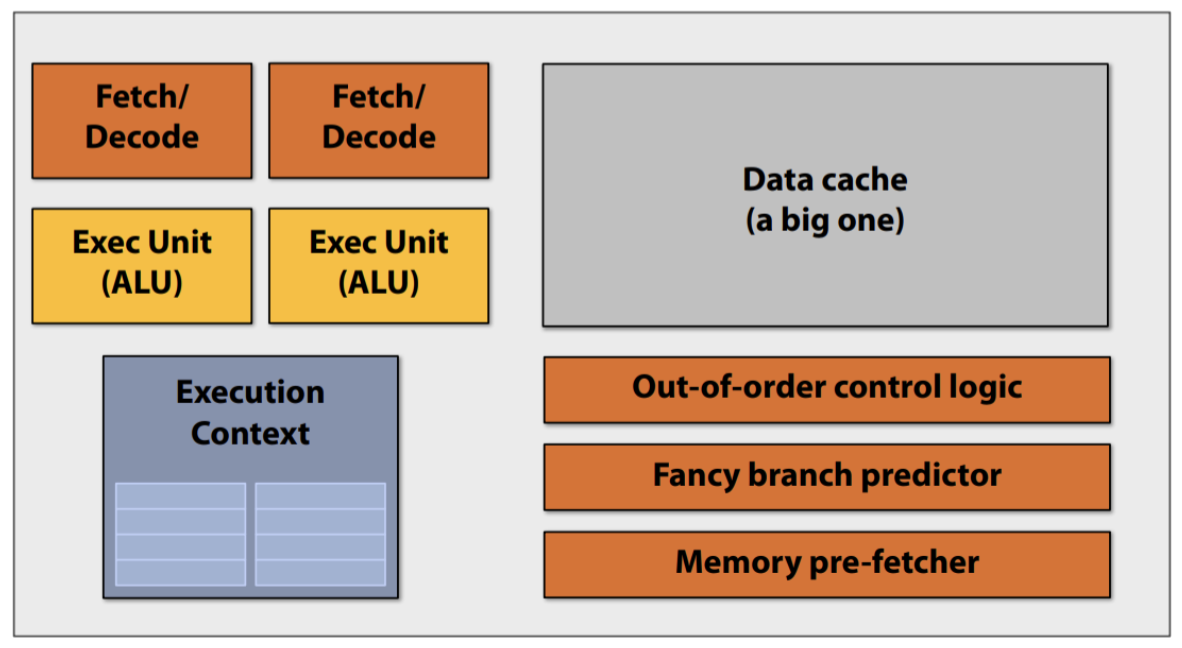
Thread Level Parallelism
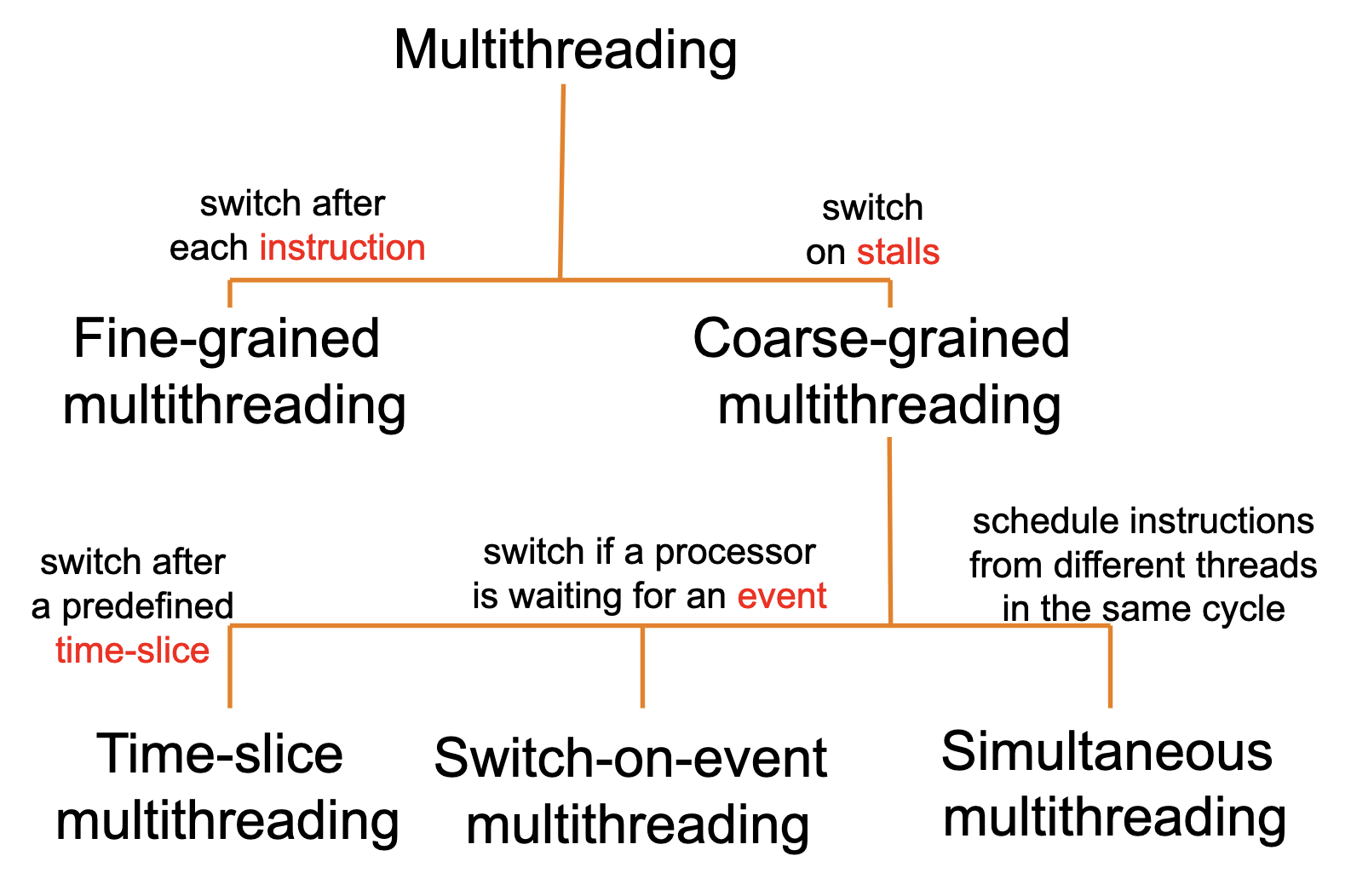
Thread Level Parallelism Hierarchy
- Processor can provide hardware support for multiple “thread contexts“: simultaneous multithreading (SMT)
- Information specific to each thread, e.g. Program Counter, Registers, etc
- Software threads can then execute in parallel
- E.g: Intel processors with hyper-threading technology, e.g. each i7 core can execute 2 threads at the same time
Processor Level Parallelism (Multiprocessing)
- Add more cores to the processor
- The application should have multiple execution flows
- Each process/thread needs an independent context that can be mapped to multiple processor cores
Flynn’s Parallel Architecture Taxonomy
Instruction stream: A single execution flow i.e. a single Program Counter (PC)
Data stream: Data being manipulated by the instruction stream
Single Instruction Single Data (SISD)
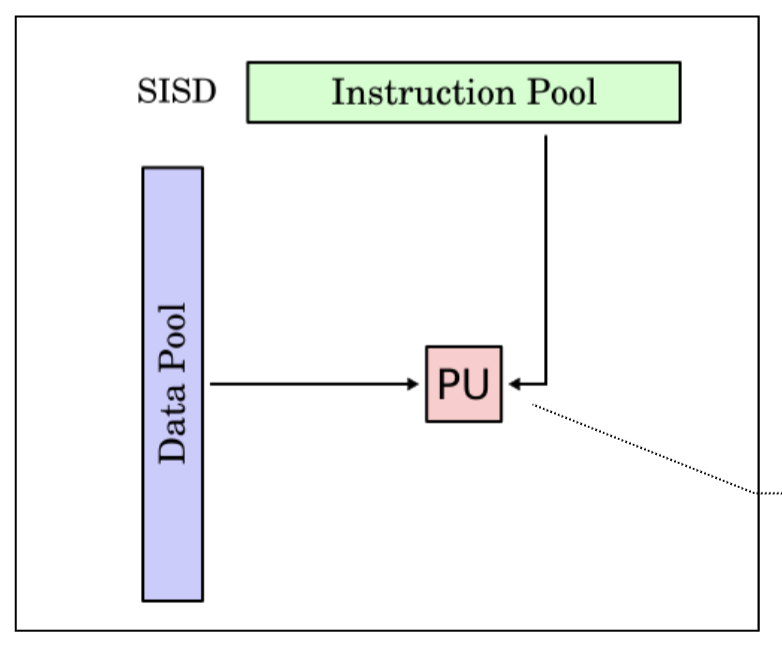
- A single instruction stream is executed
- Each instruction work on single data
- Most of the uniprocessors fall into this category
Single Instruction Multiple Data (SIMD)
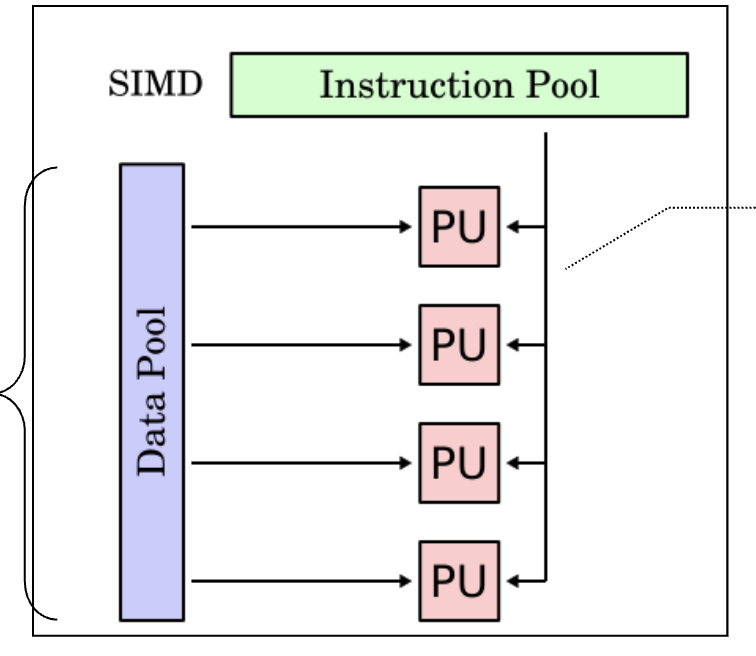
- A single stream of instructions
- Each instruction works on multiple data
- Exploit data parallelism, commonly known as vector processor
- Same instruction broadcasted to all ALUs
- Not great for divergent executions
Multiple Instruction Single Data (MISD)
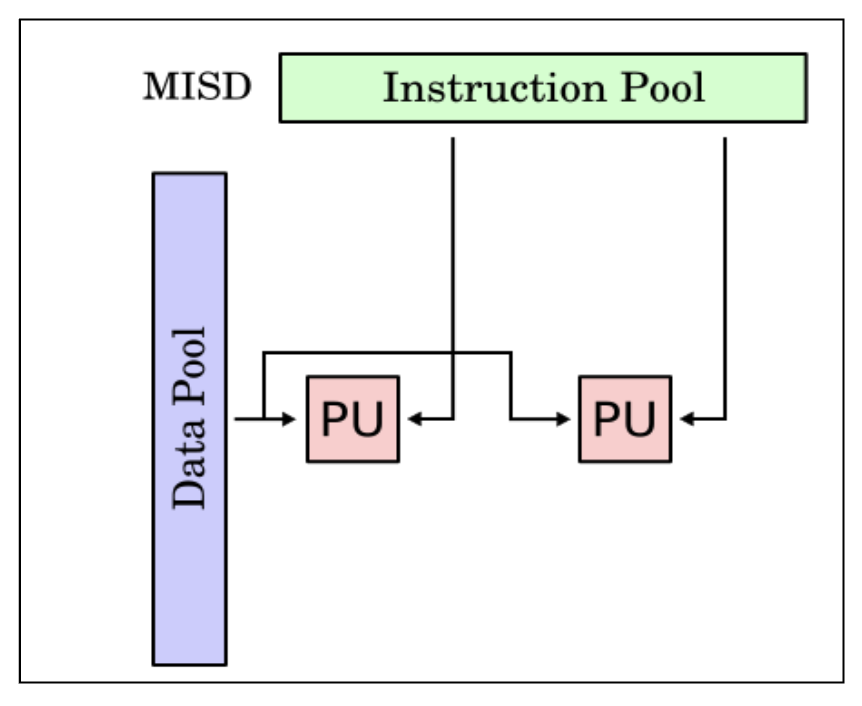
- Multiple instruction streams
- All instruction work on the same data at any time
- No actual implementation except for the systolic array
Multiple Instruction Multiple Data (MIMD)
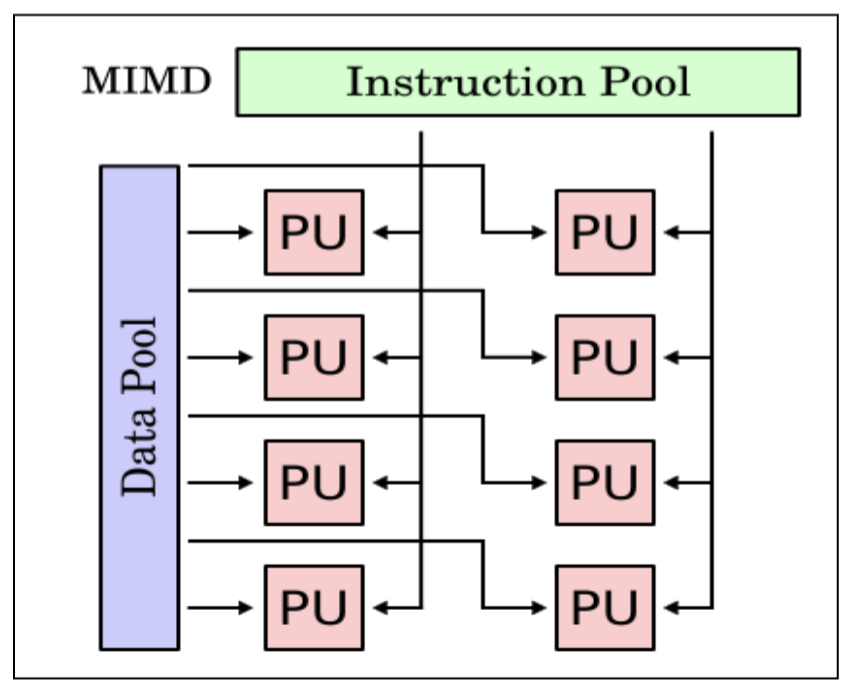
- Each PU fetch its own instruction
- Each PU operates on its data
- Currently the most popular model for multiprocessor
Multicore Architecture
Hierarchical Design
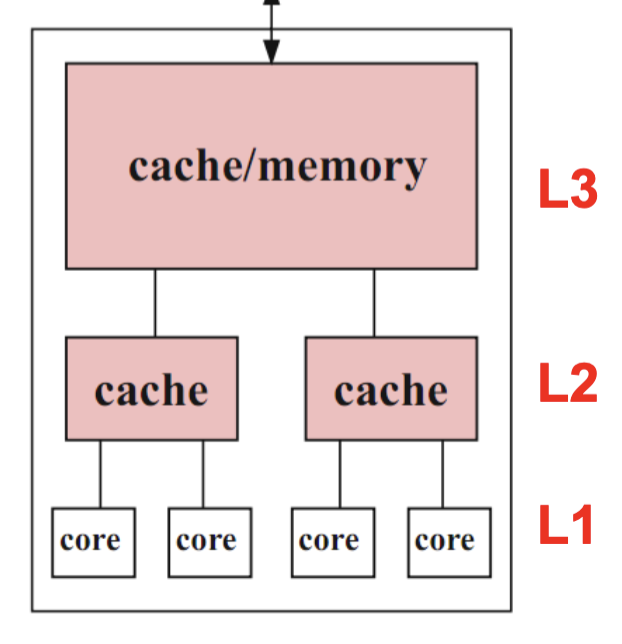
- Multiple cores share multiple caches
- Cache size increases from the leaves to the root
- Each core can have a separate L1 cache and shares the L2 cache with other cores
- All cores share the common external memory
- Usages: Standard desktop, Server processors, Graphics processing units
Pipelined Design
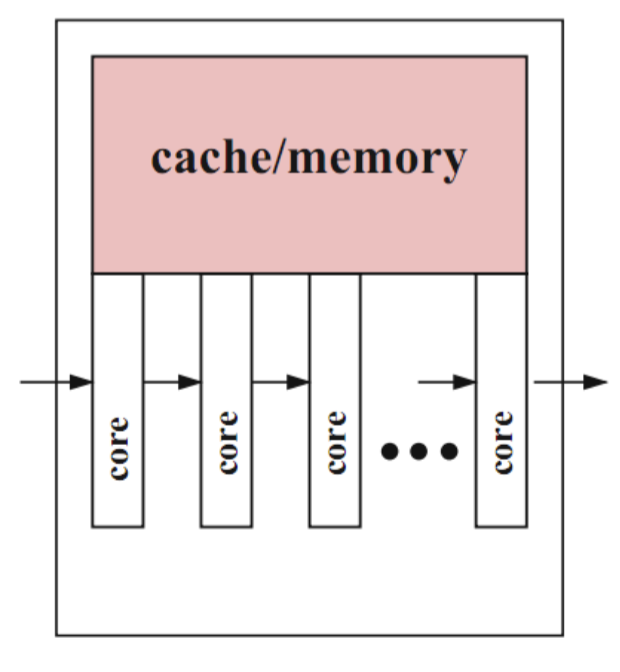
- Data elements are processed by multiple execution cores in a pipelined way
- Useful if same computation steps have to be applied to a long sequence of data elements
- E.g. processors used in routers and graphics processors
Network-based Design
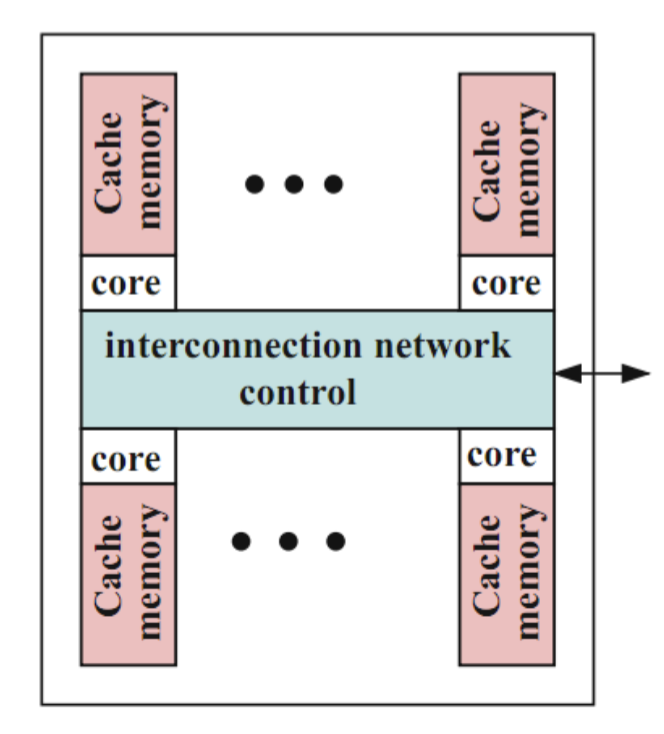
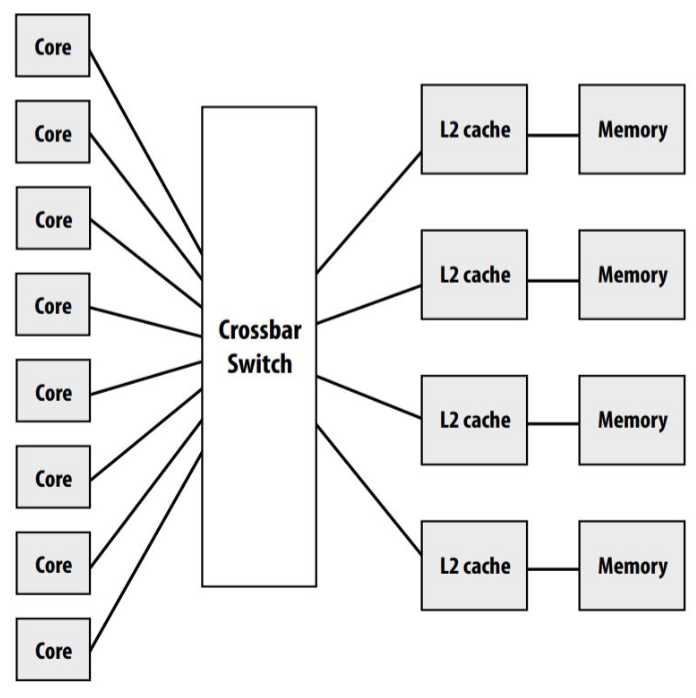
- Cores and their local caches and memories are connected via an interconnection network
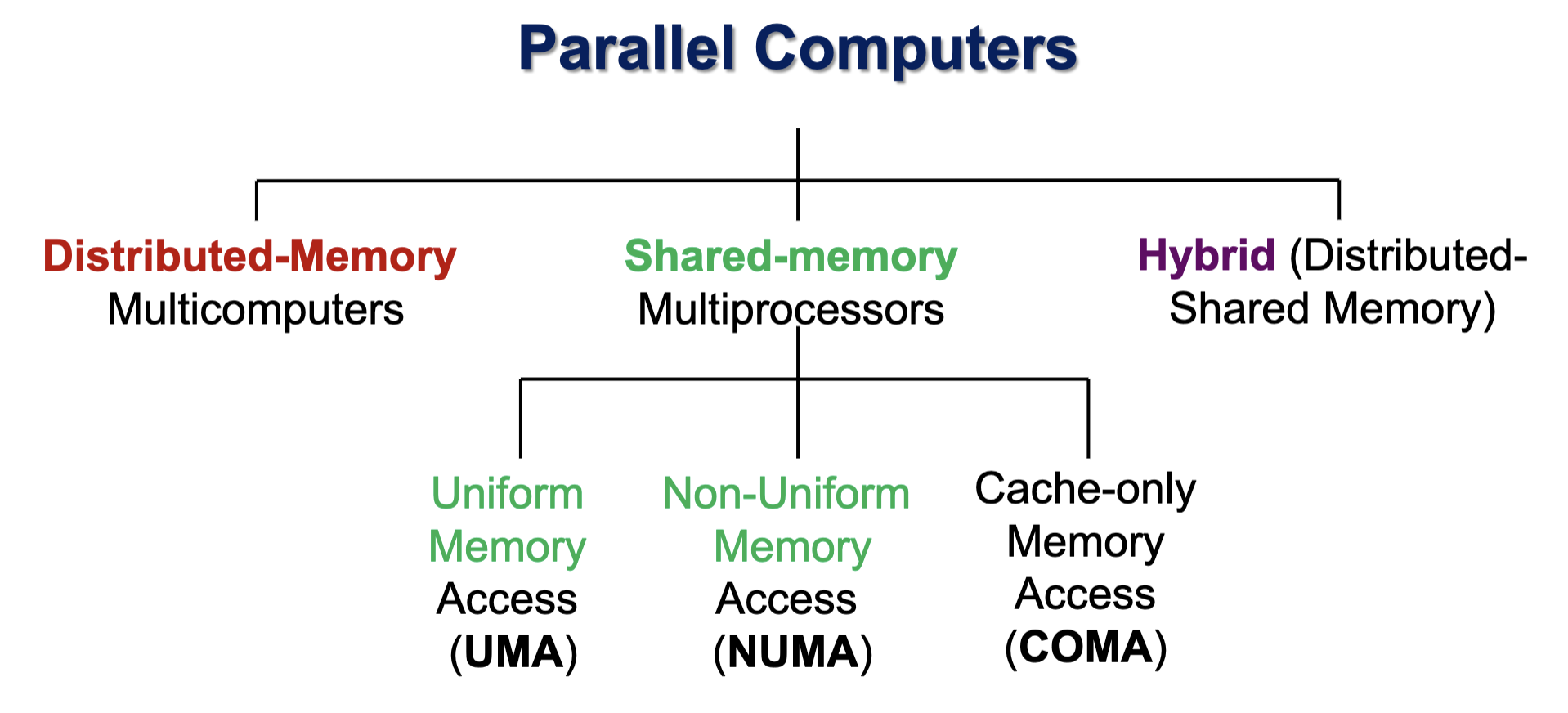
Memory Organization
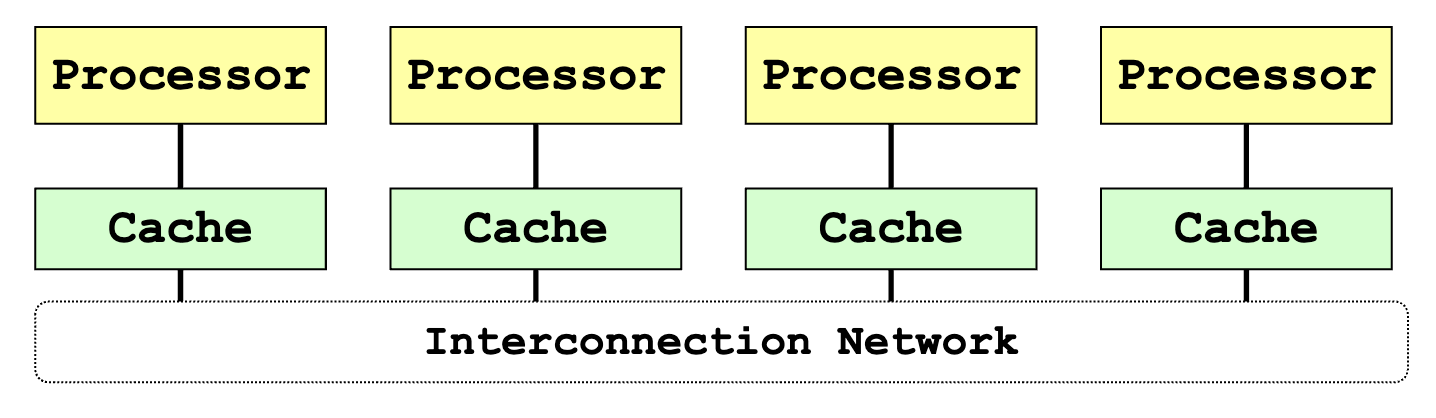
Distributed Memory System
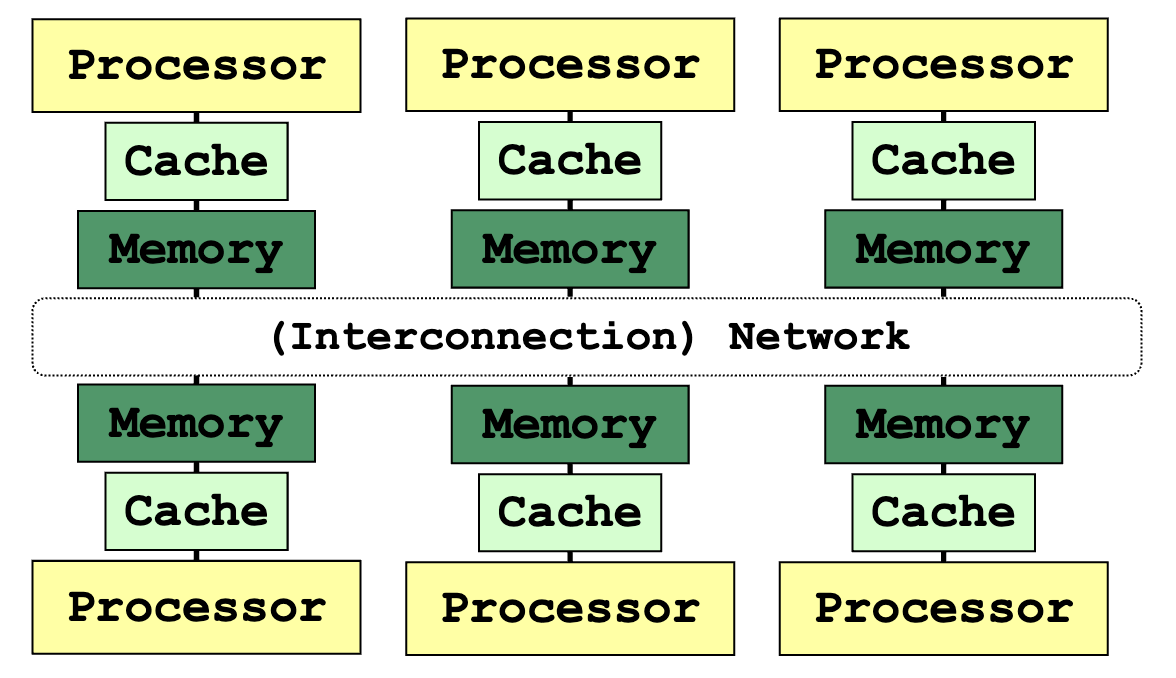
Distributed Memory System
- Each node is an independent unit
- With processor, memory and, sometimes, peripheral elements
- Physically distributed memory module
- Memory in a node is private
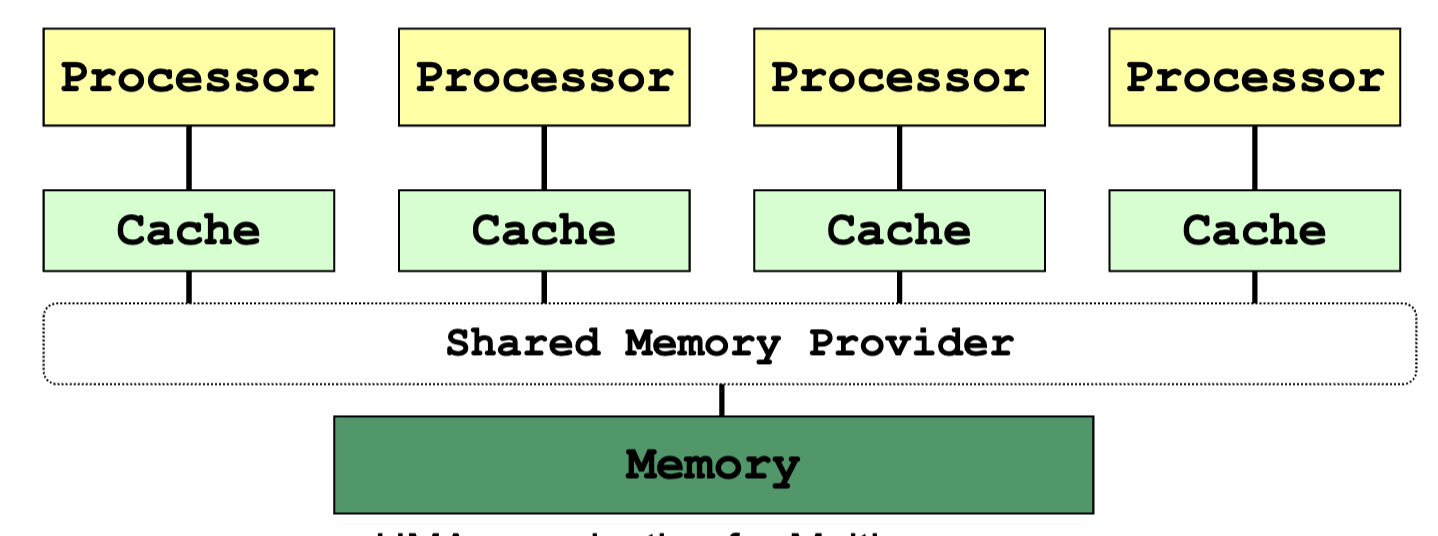
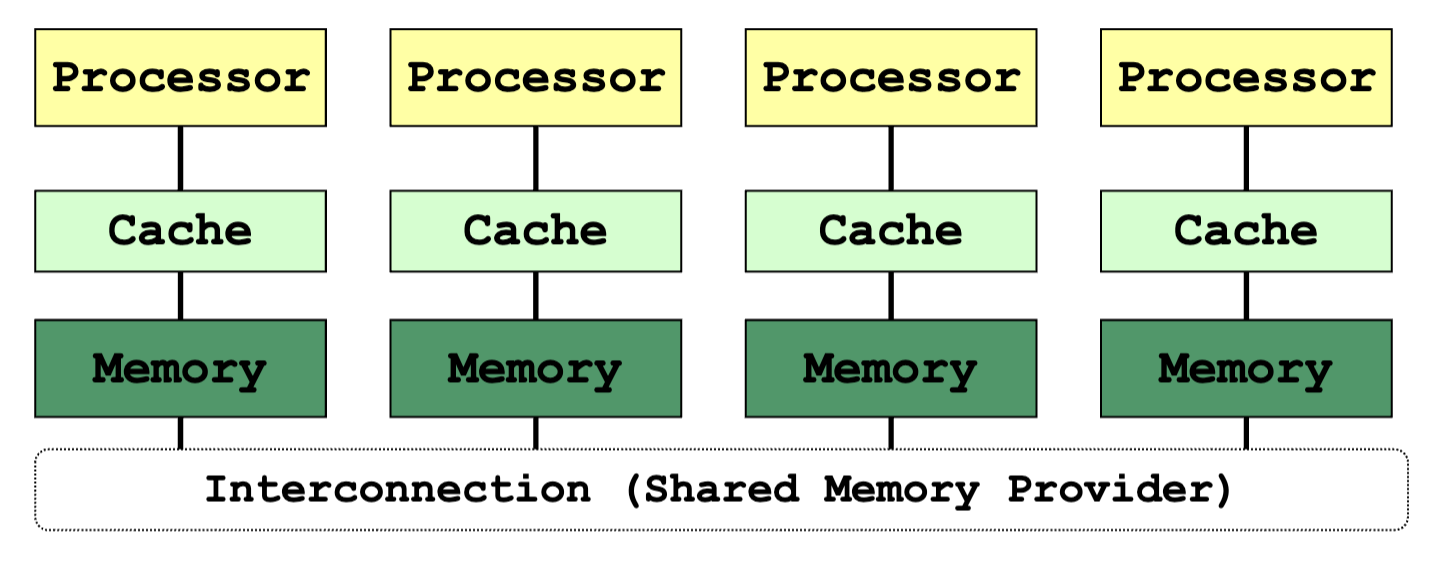
Shared Memory System
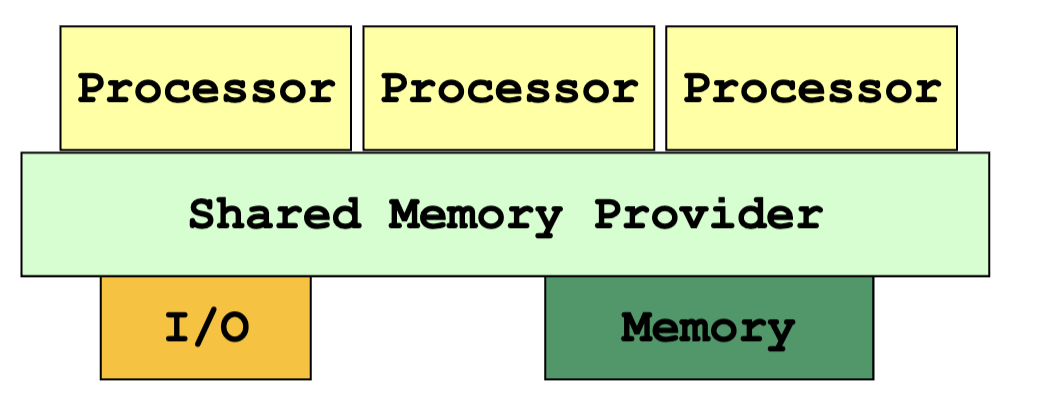
Shared Memory System
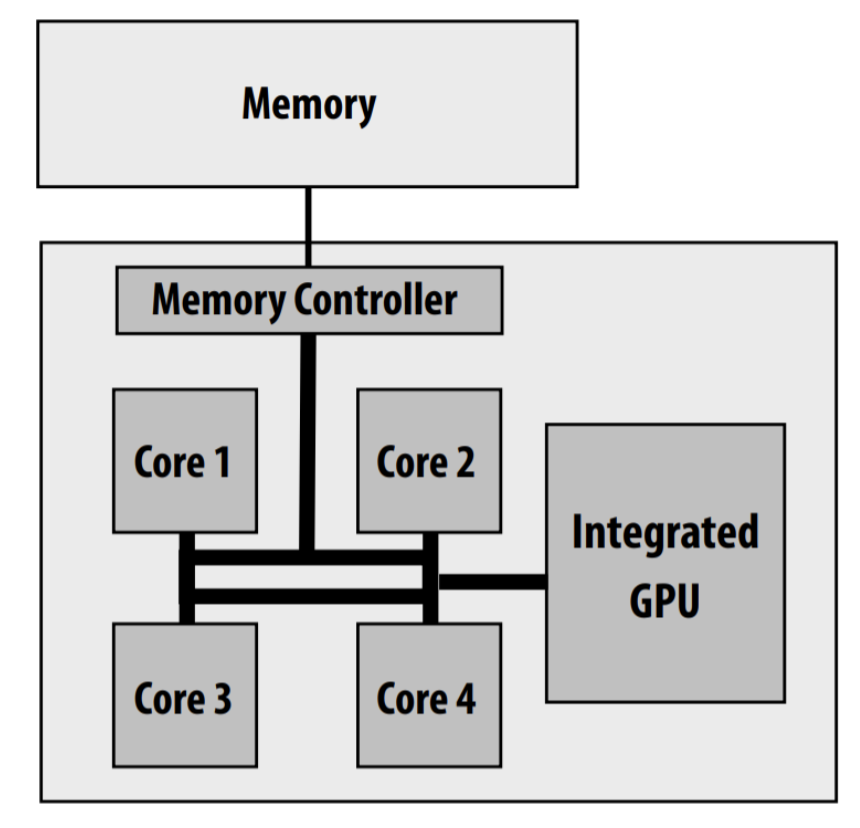
Intel Core i7 (quad core) (interconnect is a ring)
- Parallel programs / threads access memory through the shared memory provider
- Program is unaware of the actual hardware memory architecture
- Cache coherence and memory consistency
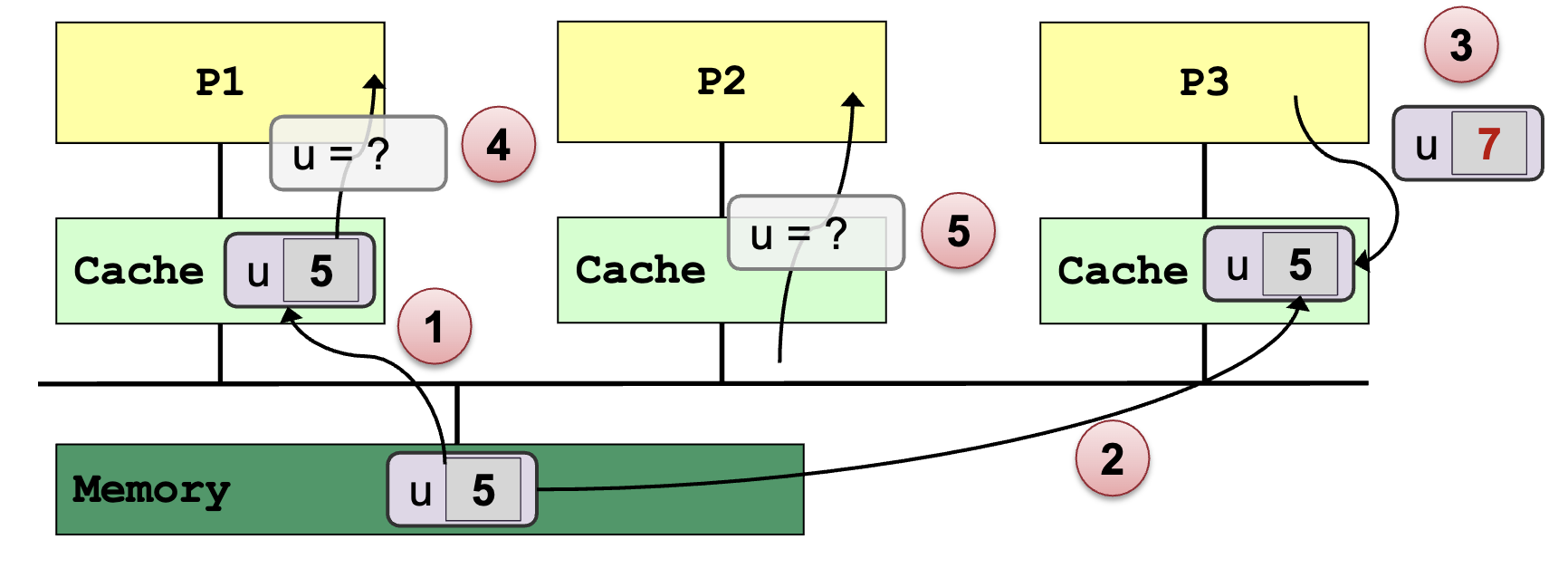
Cache Coherence:
- Multiple copies of the same data exist on different caches
- Local update by processor → Other processors should not see the unchanged data
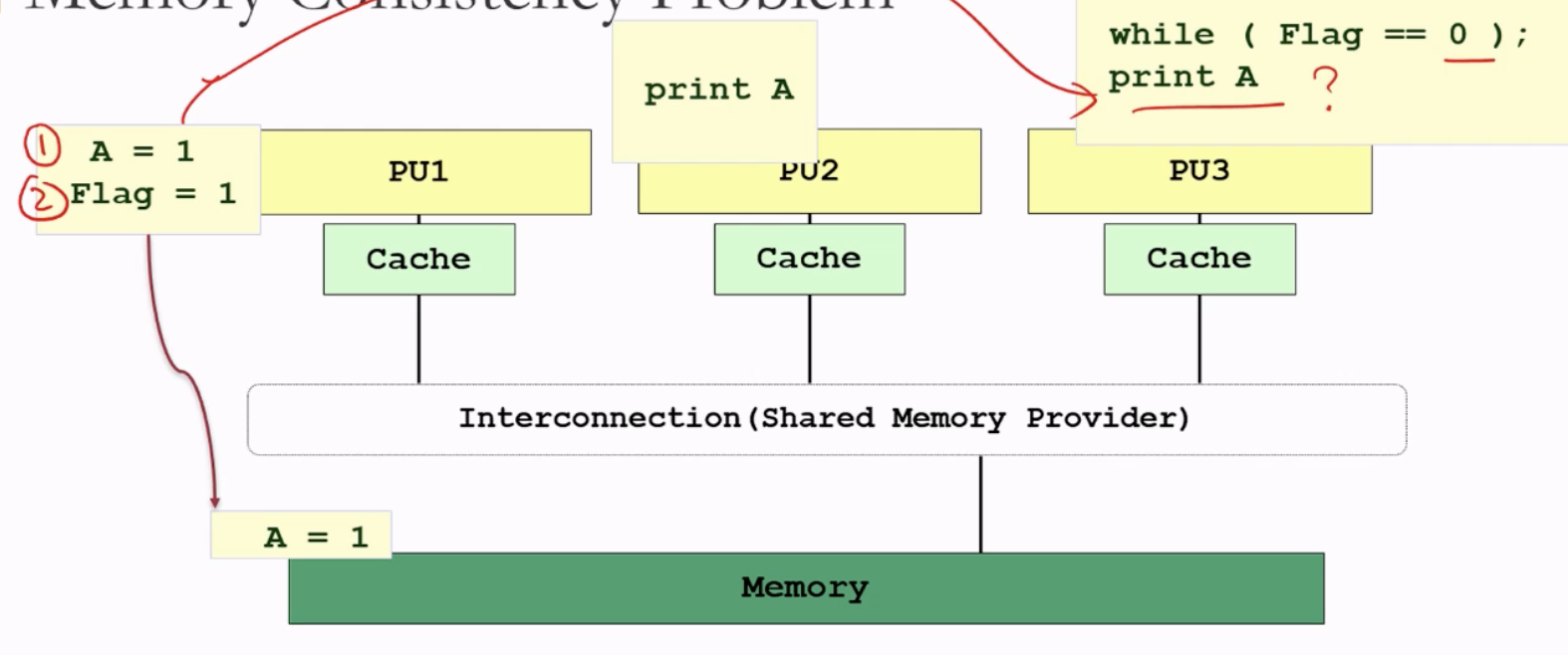
Memory Consistency:
Uniform Memory Access (Time) (UMA):
- Latency of accessing the main memory is the same for every processor
- Suitable for small number of processors – due to contention
Non-Uniform Memory Access (NUMA):
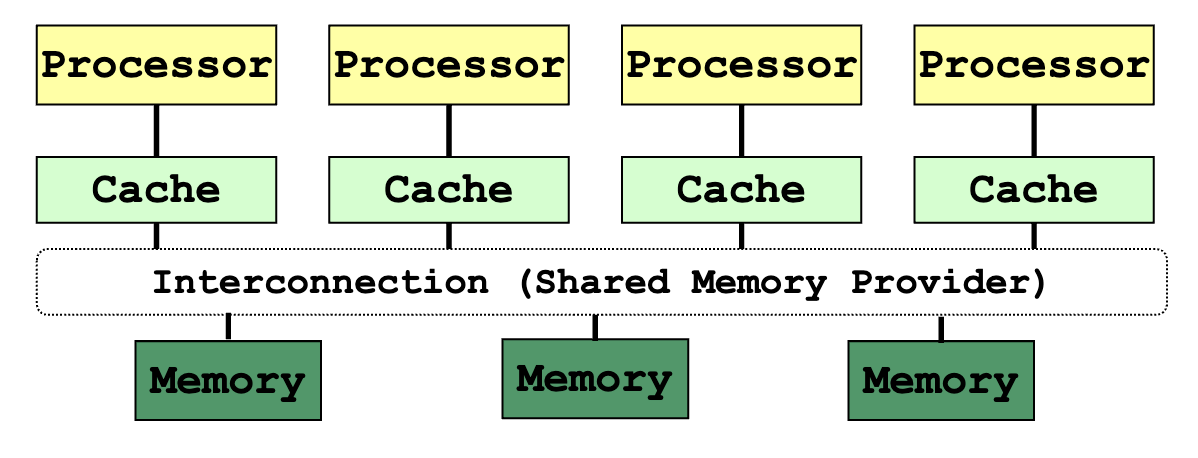
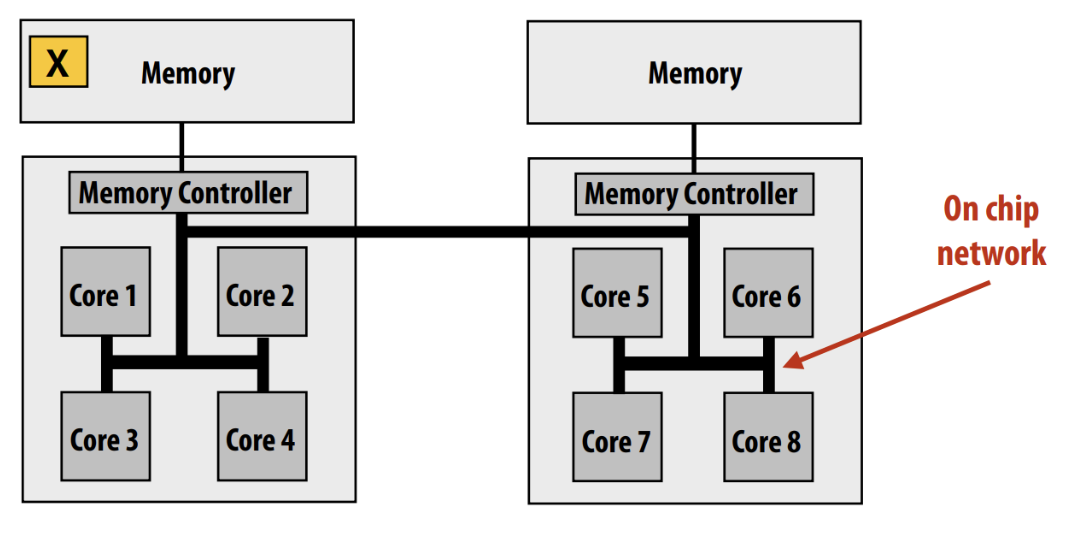
Modern multi-socket config
- Physically distributed memory of all processing elements are combined to form a global shared-memory address space
- also called distributed shared-memory
- Accessing local memory is faster than remote memory for a processor
ccNUMA:
- Cache Coherent Non-Uniform Memory Access
- Each node has cache memory to reduce contention
COMA:
- Cache Only Memory Architecture
- Each memory block works as cache memory
- Data migrates dynamically and continuously according to the cache coherence scheme
Advantages:
- No need to partition code or data
- No need to physically move data among processors → communication is efficient
Disadvantages:
- Special synchronization constructs are required
- Lack of scalability due to contention
Hybrid (Distributed-Shared Memory)
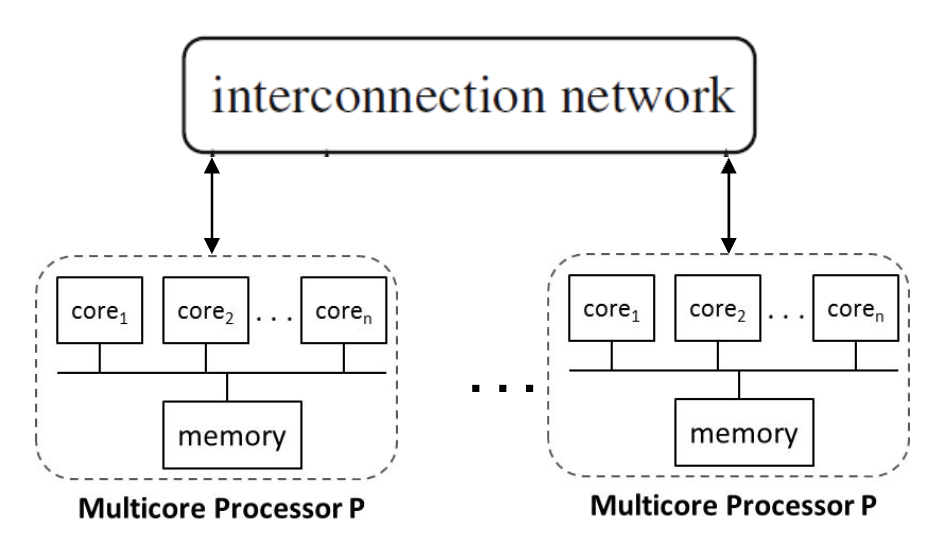
Hybrid with Shared-memory Multicore Processors
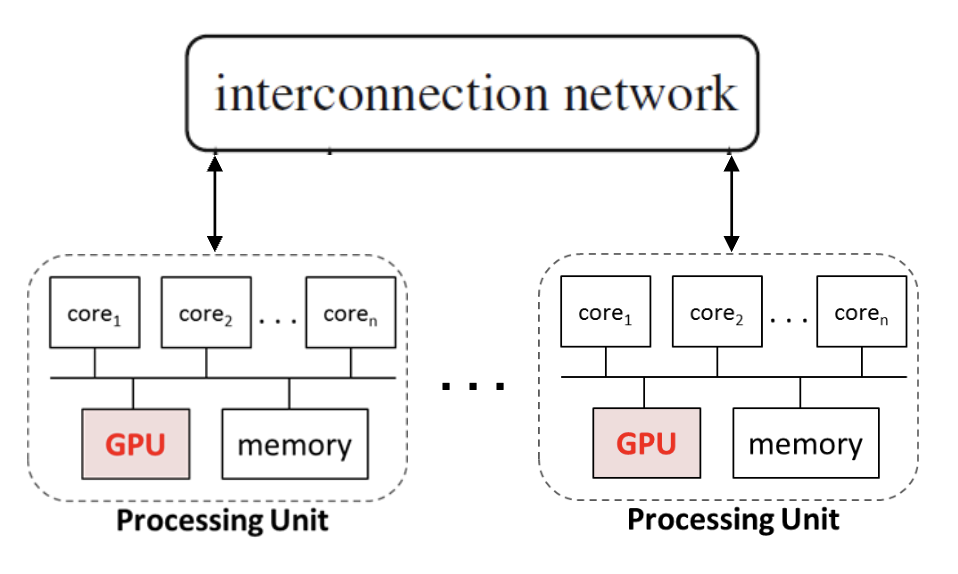
Hybrid with Shared-memory Multicore Processor and GPU