CS4243 Final notes
Basic operations
Pixel‐wise Operations
Transform a into b:
E.g: Histogram manipulation, Grayscale modification, Image normalization
Grayscales modification
Find max and min gray level:
Dynamic range of a:
Change to by:
Brightness: The measured intensity of all the pixels comprising an ensemble that constitutes the digital image after it has been captured, digitized, and displayed.
Contrast: The amount of color or grayscale differentiation that exists between various image features in both analog and digital images.
Histogram
Application: Histogram equalization, Histogram‐based color reduction, Used as a feature vector, Template matching
Histogram equalization
- Original image has got
Npixels,Ggray levels, and should be converted to an image withKgray levels with uniform distribution. - Start from the lowest gray level,
g=0, k=0. - Accumulatively count the number of pixels in gray levels and increase g, g++.
- When the accumulated number of pixels gets to N/K, assign a new gray level, k, to that group.
- g++, k++, number of pixels counter=0.
- Continue from 3
Template matching algorithm
- Key image
k, its histogramh_k, input imagea, its histogramh_a. - The Numbers of gray levels are equal in
kanda. - Apply histogram equalization on
a, results area1,h_a1. - Use cumulative distribution of gray levels in
k, try to put the equal number of pixels in the bins ofa2,a -> a1 -> a2. the goal is to maximize the similarity between cumulative distribution ofh_kandh_a2.
Convolution
Properties: Commutative → . Associative → . Distributive →
Lowpass filter
Make the image less noisy but blur.
Gaussian filter:
Padding: Zero padding vs. Average padding vs. Random padding
Stride: #steps we are moving in each step in convolution (1 by default)
m*m image convolve with n*n kernel, output is of size (m-n+1) * (m-n+1)
- If padding
pthen(m + 2*p - n + 1)*(m + 2*p - n + 1) - If stride
sthen((m + 2*p - n + 1)/s + 1)*((m + 2*p - n + 1)/s + 1)
Median Filter
Can use mode instead. Good in dealing with dot (salt & pepper) noises. No unsharping/blurring effect. Patch size variant
Noise
White noise: a random signal having equal intensity at different frequencies, giving it a constant power spectral density.
Presence of noise in an image might be additive or multiplicative.
Dot noise: Mostly result of the multiplication of a [0,1] or [1,255] matrix with your image. Could be due to channel disconnection or saturation.
Signal to Noise Ratio:
Calculated in , Noise power is often calculated by
Highpass Filter
Typically a gradient or differentiation operator, tend to be differential and derivative operators (1st or 2nd order).
Discrete 1st derivative:
Discrete 2nd derivative:
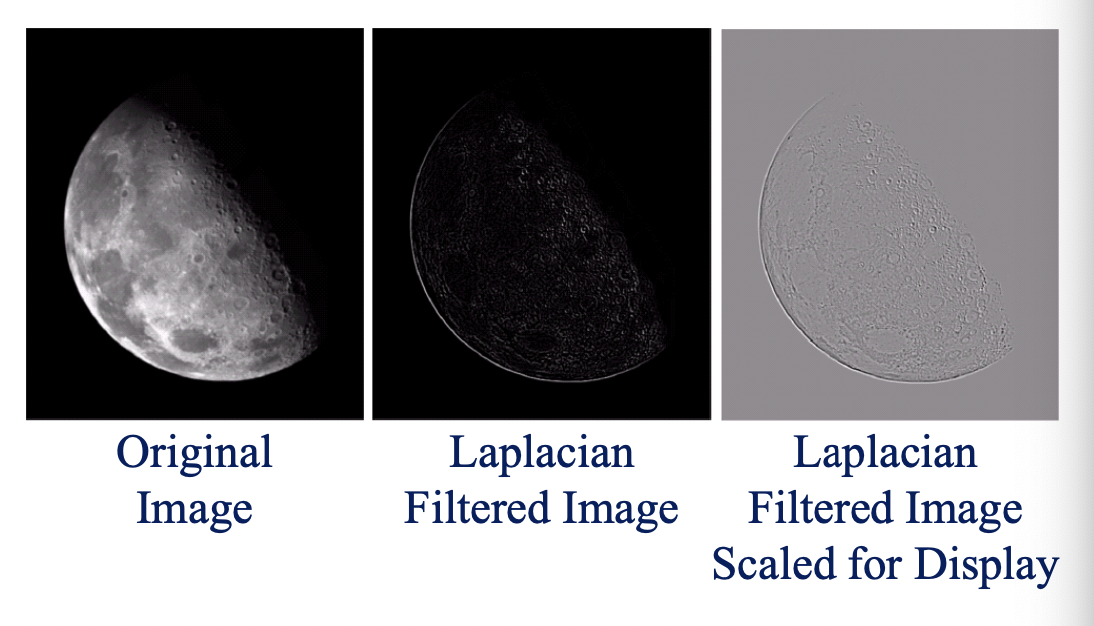
Laplacian:
Laplacian Filter:
Sobel Operator
Edge strength map:
Edge direction map:
Apply thresholding ( is the threshold):

Many things can be done with and : Finding the strongest edges and their direction, border tracking and vectorization
Diagonal edge detection:
→ Mathematically it’s a bit problematic due to the lack of orthogonality, but practically it’s not bad.
Unsharp masking
Edge enhancement algorithm

Image Energy, Power, and Entropy
is the probability associated with gray level . Entropy of an img measures the degree of randomness in the img → noisy img has higher entropy than original img
Image transform
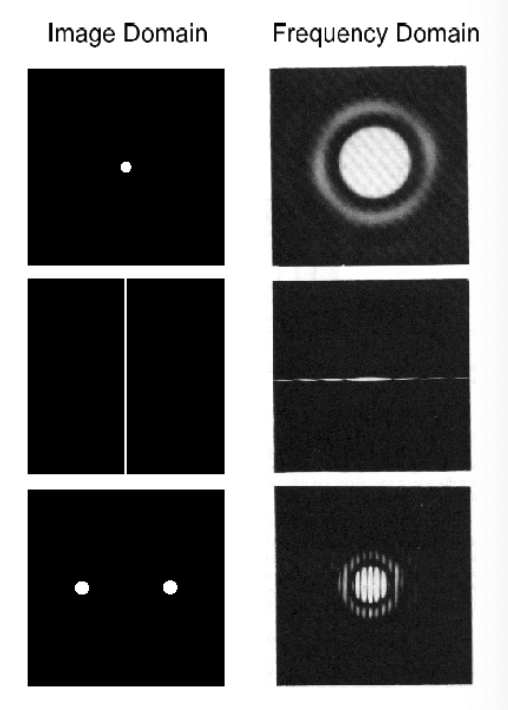
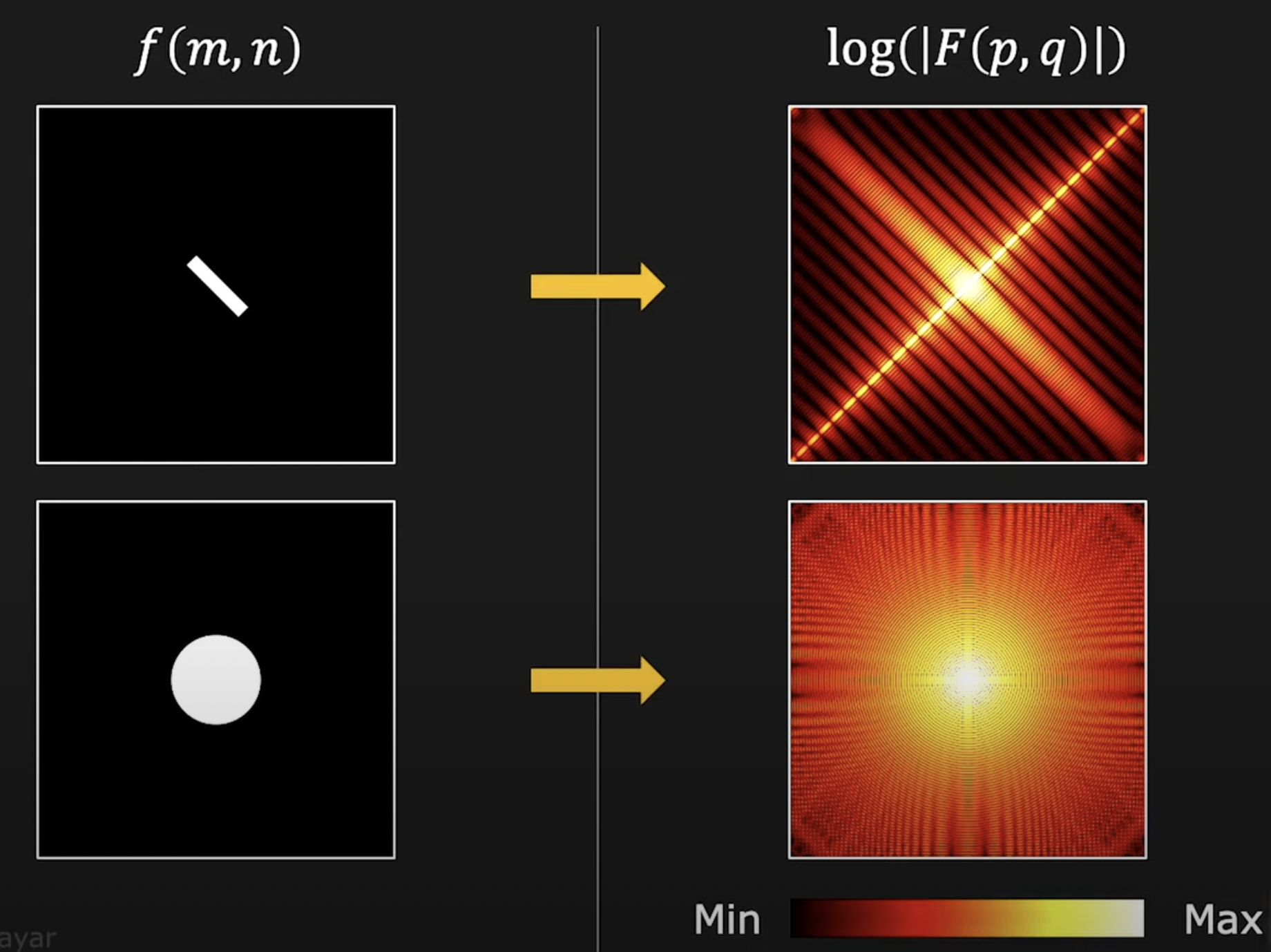
Fourier transform
Continuous:
Discrete:
where:
FFT is a one-to-one and invertible transform

Power spectrum density: PSD = Magnitude of Fourier transformed
Phase → which components are present (more important). Magnitude → contributions of each components.

Frequency domain filters
Ideal:
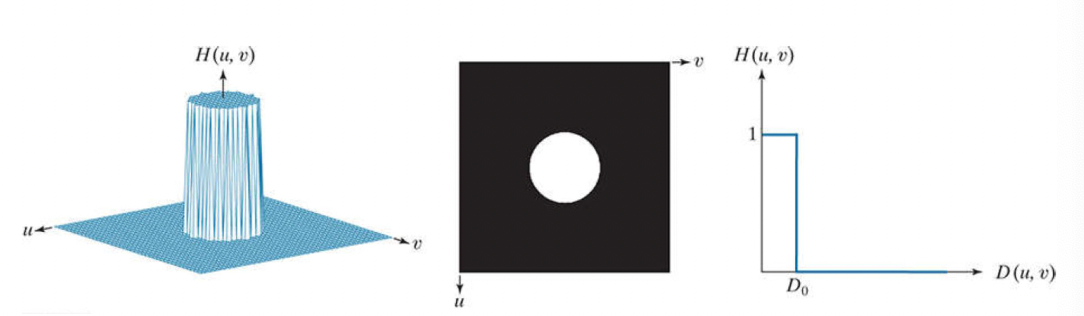
Gaussian:

Butterworth:
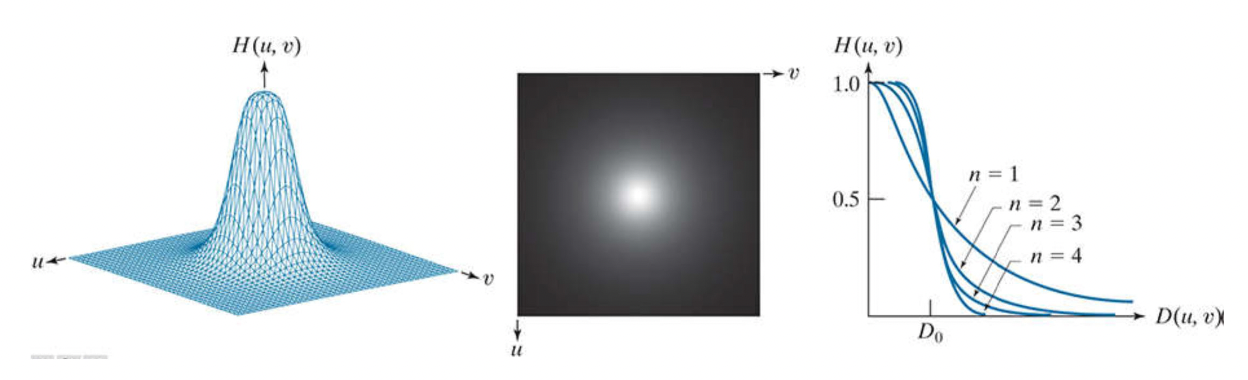
n = order of the Butterworth filter
= distance to the frequency axes origin
= filter bandwidth or coordination of the cut‐off point
Filter matrix size = image size = Fourier Transform matrix size
Cut-off point: where the magnitude of the filter raeches 0.5
Corresponding high pass filter obtains by 1‐LPF
Ideal filter → cause sidelobes and distortion
Lowpass Filter
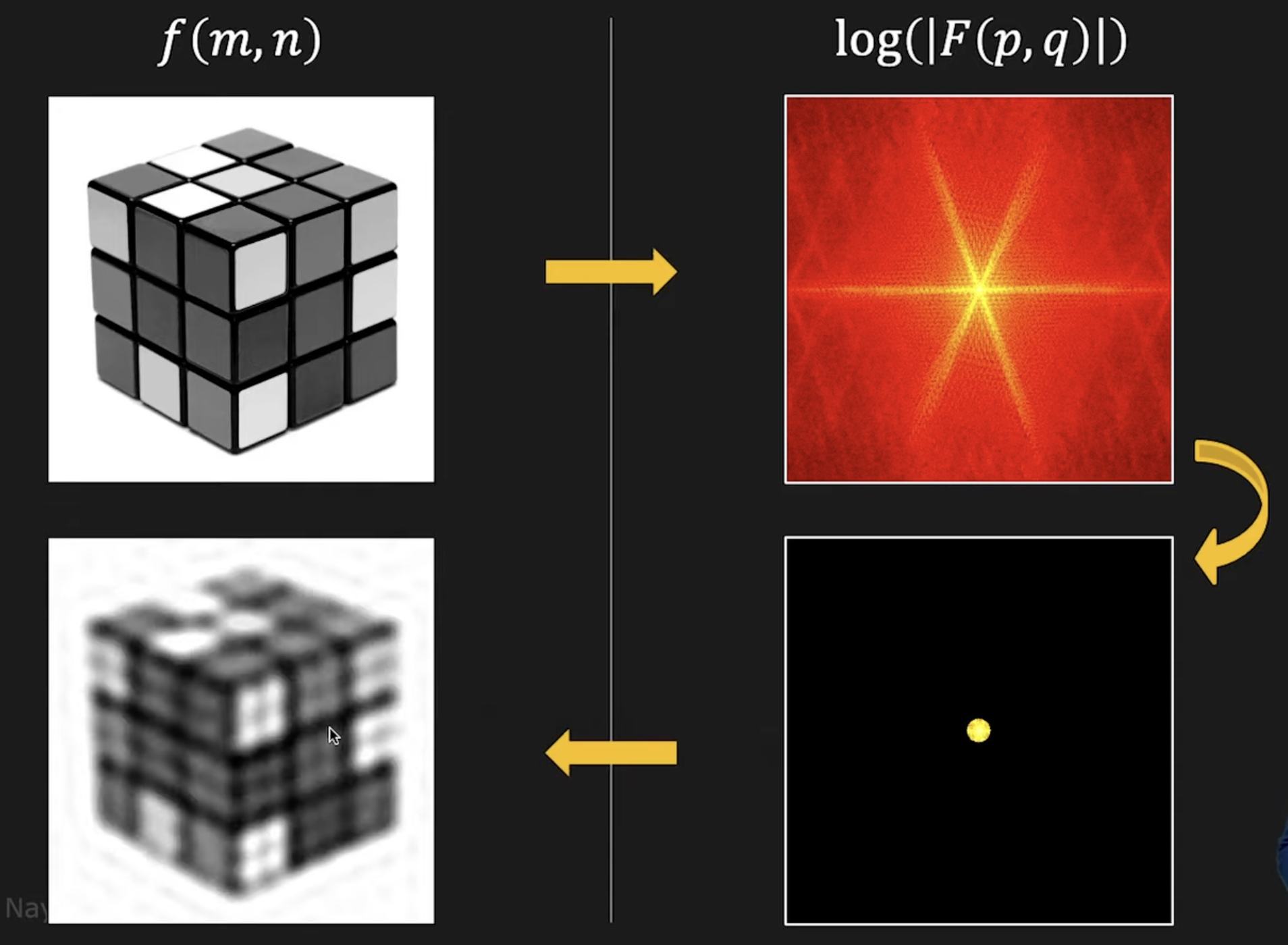
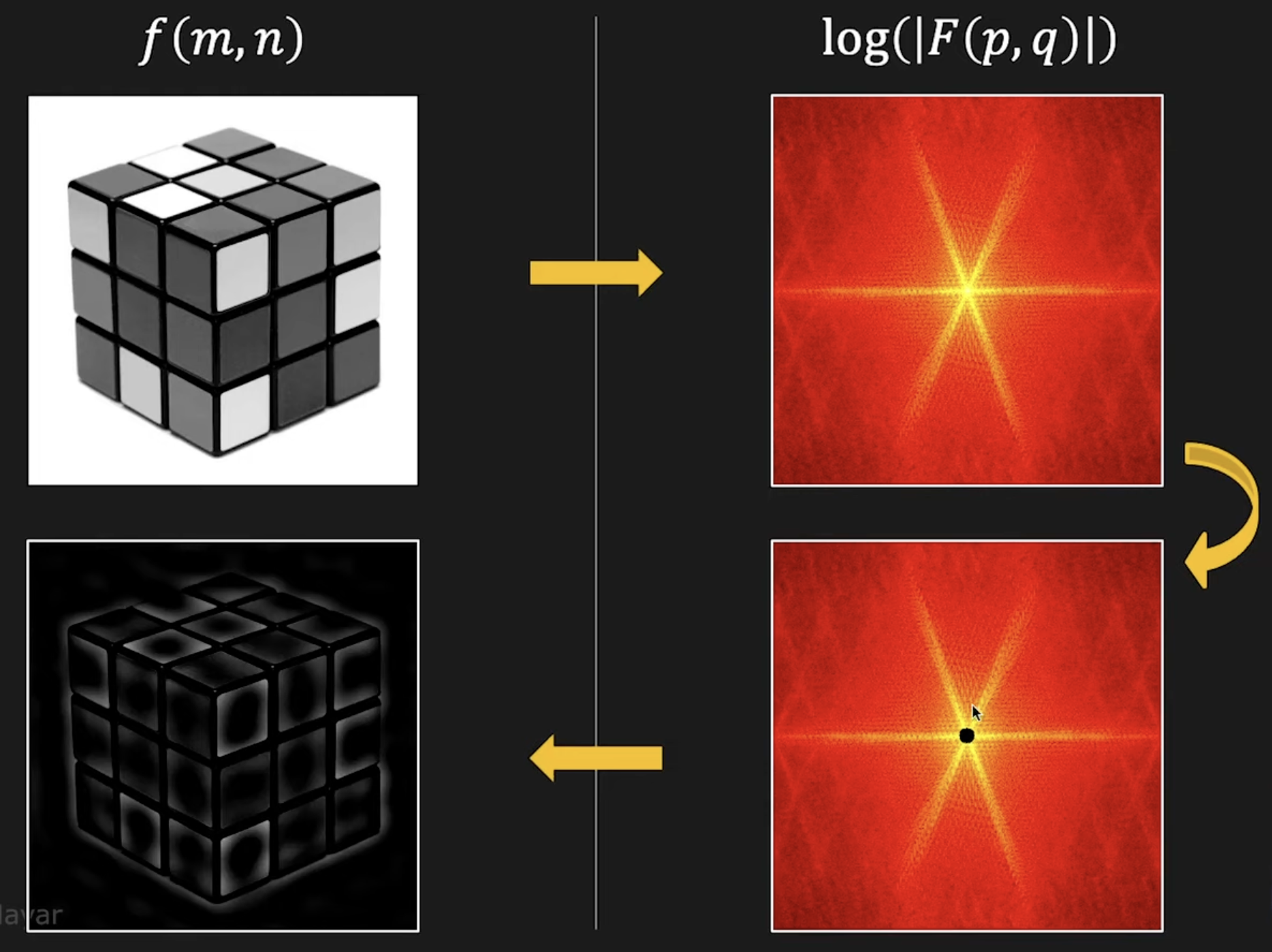
Walsh/Hadamard Transform

Use real square wave kernels → faster and computationally lighter
Hadamard transform: matrix-based Walsh transform, applicable when the input image is
User term ‘Sequence’ instead of frequency, where S=2F
Hadamard Transform
Natural Hadamard matrix:
Natural Hadamard transform:
Since , and .
A coefficient is necessary for the transform
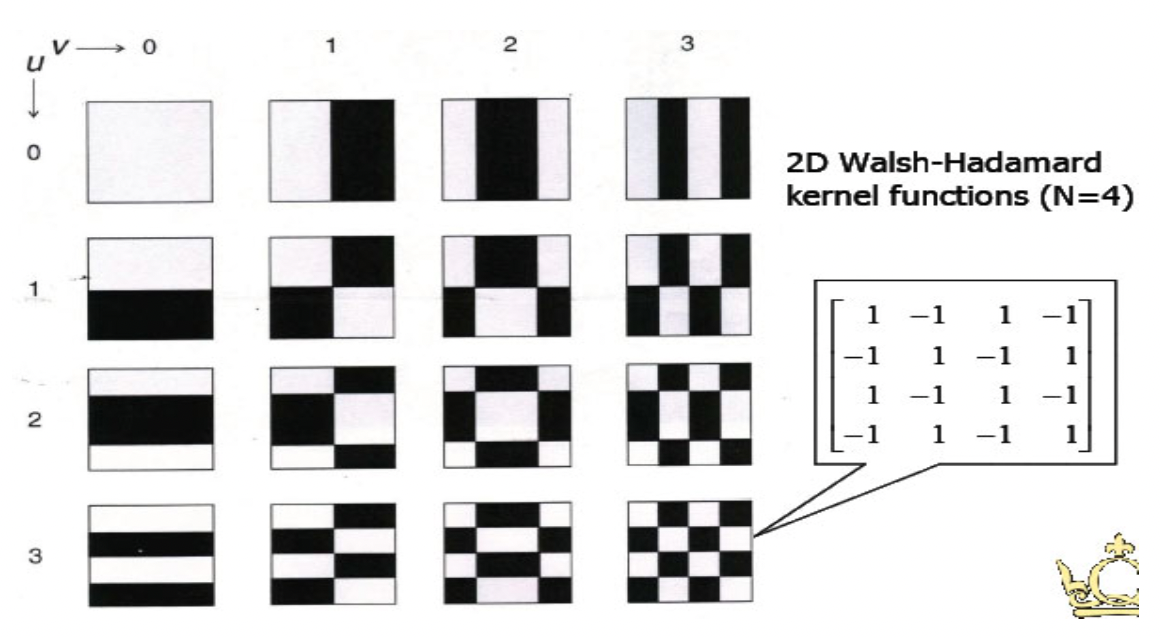
Sequence-ordered Hadamard matrix (reorder rows in increasing number of sign changes):
is the sum of all pixels in the original images
Discrete Cosine Transform

Cosine transform kernel functions are not complex.
Hough Transform
Line in img space: → Point in parameter space:
Point in img space → Line in parameter space
Colinear points → Intersecting lines
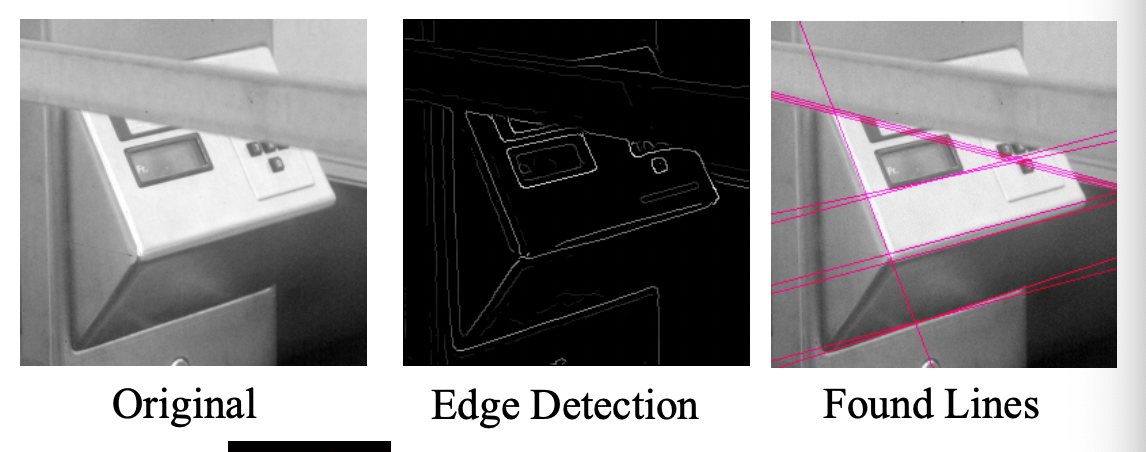
At each point of the (discrete) parameter space, count how many lines pass through it using an array of counters. The higher the count, the more edges are collinear in the image space. Find a peak in the counter array.
Practical difficulties:
- The slope of the line is → Param space is infinite
- does not express lines of the form
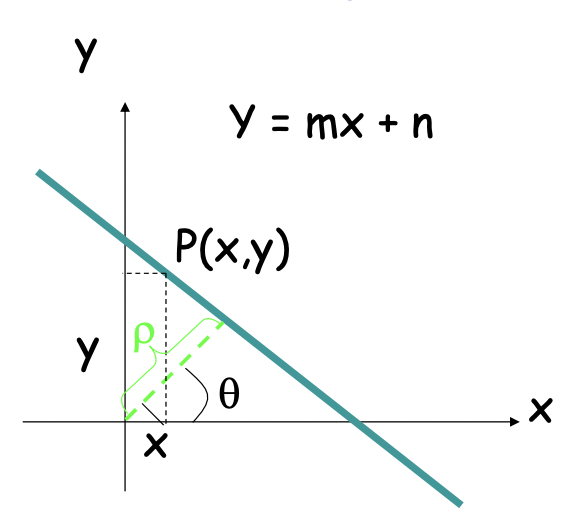
Solution: Use normal equation of a line
The new param space is finite as where D is the image diagonal, and
It can represents all line: with and with
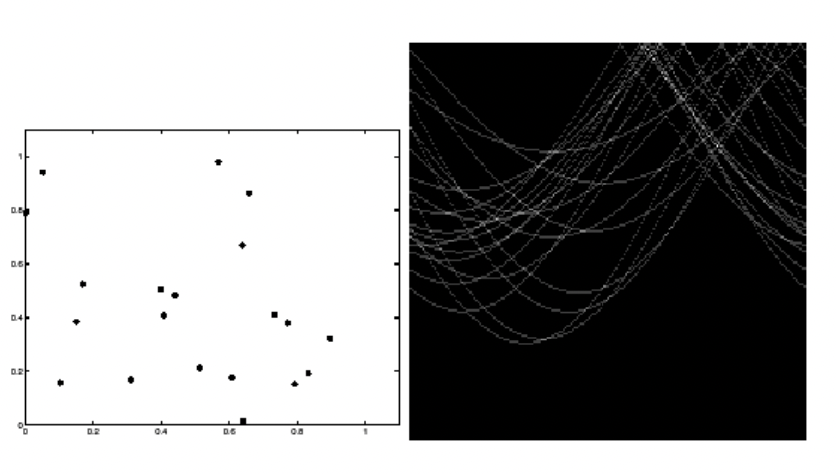
A point in image space is not represented as a sinusoid:
Hough Transform Algorithm
Input is an edge img: E[i, j] = 1 for edges
Discretize and in increments of and . Let A[R, T] be an array of integer accumulators initialized to 0
For each pixel E[i, j] = 1 and h = 1, 2, 3, ..., T do
- Find the closest integer k corresponding to
- Increment counter
A[h, k]by1
Find local maxima in A[R, T]
→ Can speed up if we now the orientation of the edge, can allow orientation uncertainty by incrementing a few counters around the nominal counter.
→ Can be generalized for curves where are the parameters.
Color spaces
RGB color space
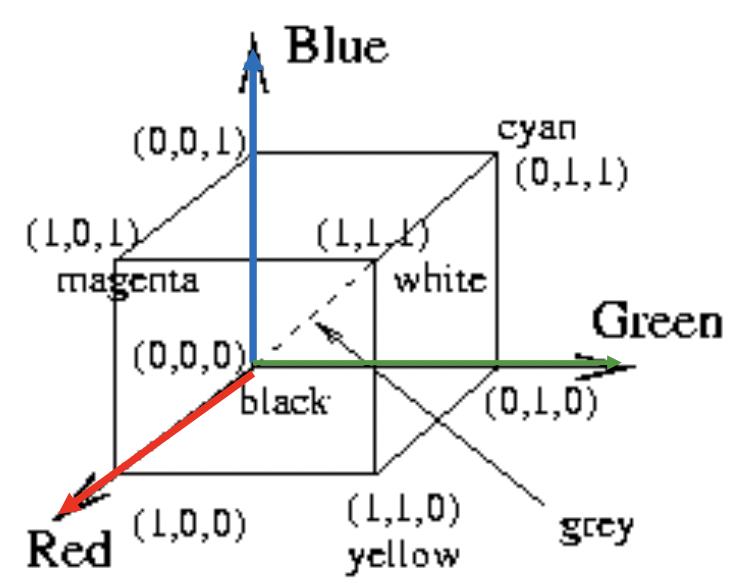
RGB values normalized to
Human perceives gray for triples on the diagonal
“Pure” color on corners
HSI/HSV color space
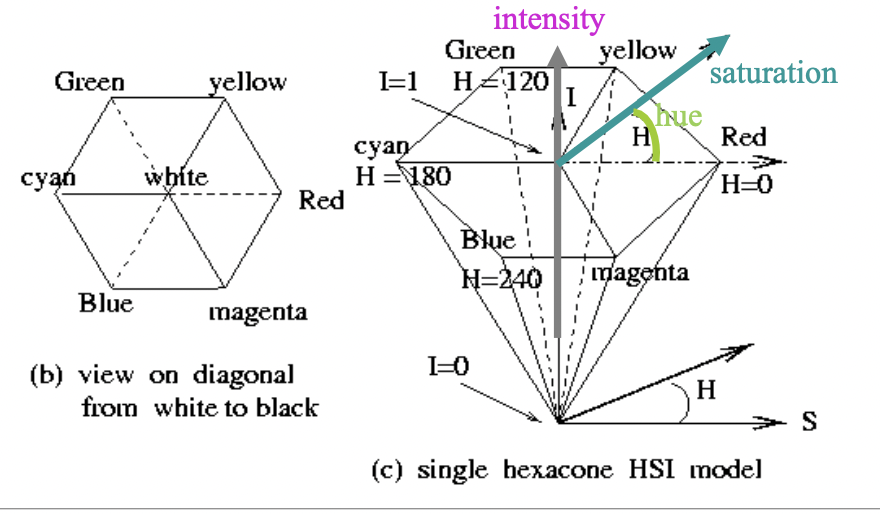
H and S ancodes chromaticity. Hue is defined by the angle. S models the purity of the color (S=1 for a completely pure or saturated color and S=0 for a shade of gray)
YIQ and YUV for TV signals
Have better compression properties. Luminance Y encoded using more bits than chrominance values I and Q, humans are more sensitive to Y than I, Q.
Luminance → often used for color to grayscale conversion
CIELAB color space
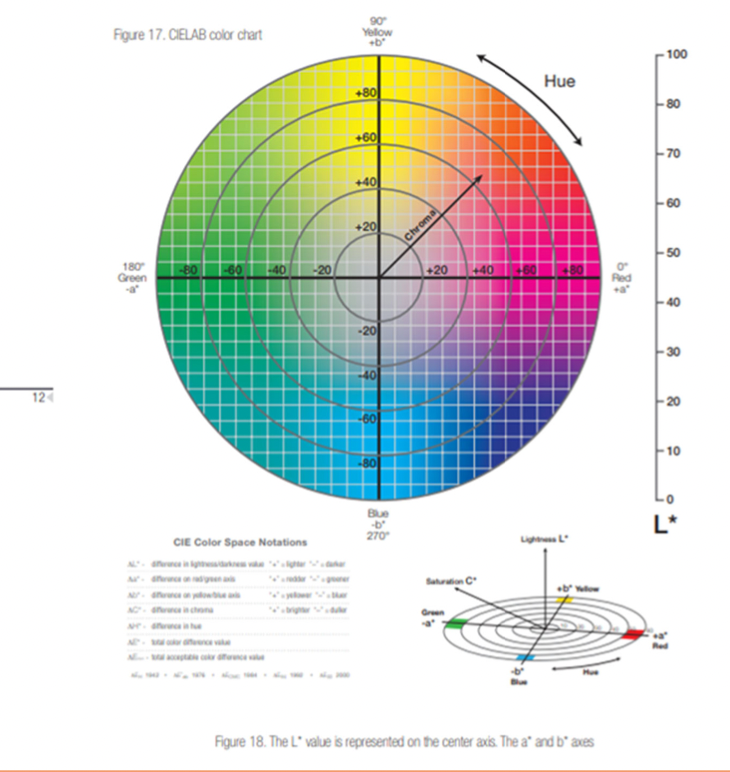
L*: Lightness
a*: Red/Green value
b*: Blue/Yellow value
+a direction → shift towards red
+b direction → shift towards yellow
L=0 → black or total absorbtion
Center of the plane is gray or neutral
Hue: , Chroma:
Texture Analysis
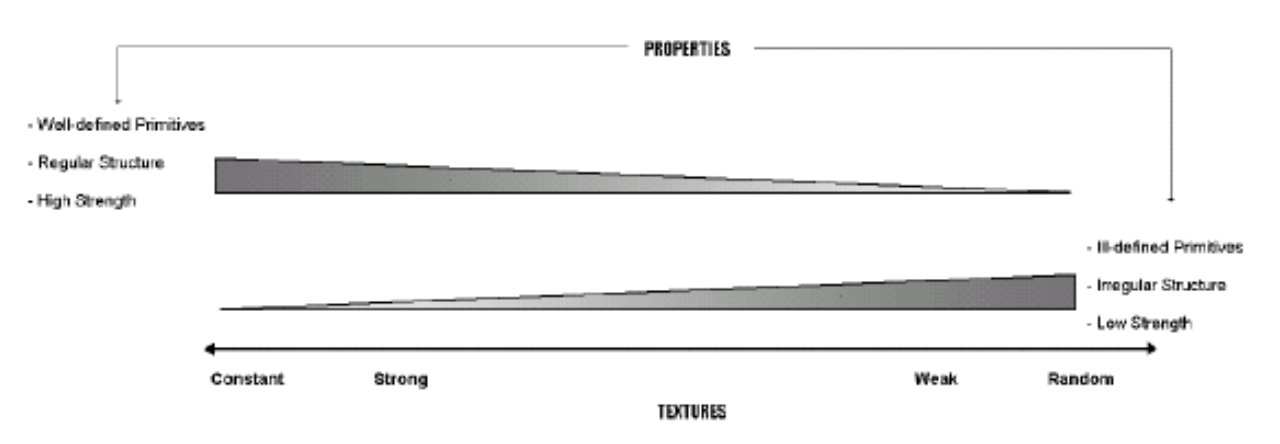
Categories
Statistical methods
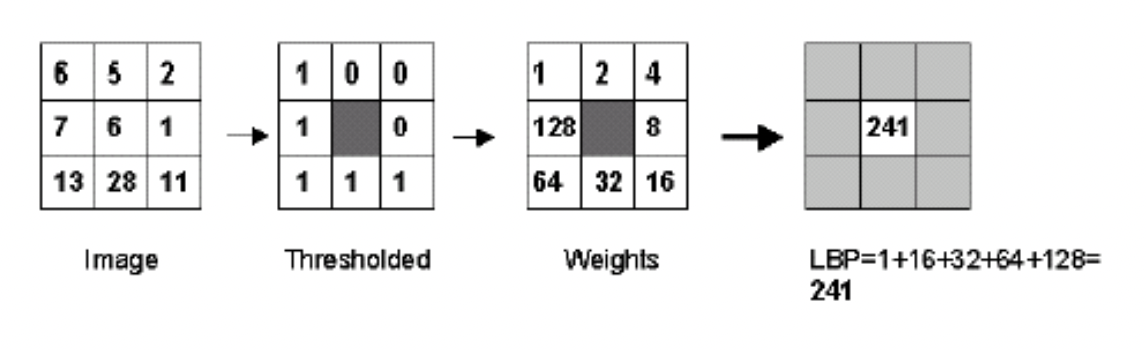
Local binary pattern (LBP)
Gray level co-occurrence matrix (GLCM)
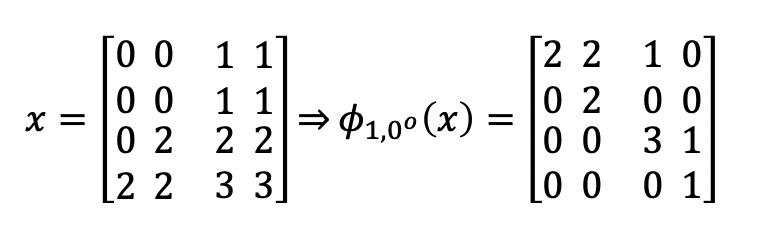
Usually (clockwise) and
Functions to be applied on GLCMs:
are basic statistic of . Entropy measures the texture homogeneity. Correlation measures img linearity metric, large correlation in direction → linear directional structures in direction . IDM measures the extent to which the same tone tends to be neighbors. Inertia (or Contrast) is a texture dissimilarity measure.
Signal processing methods
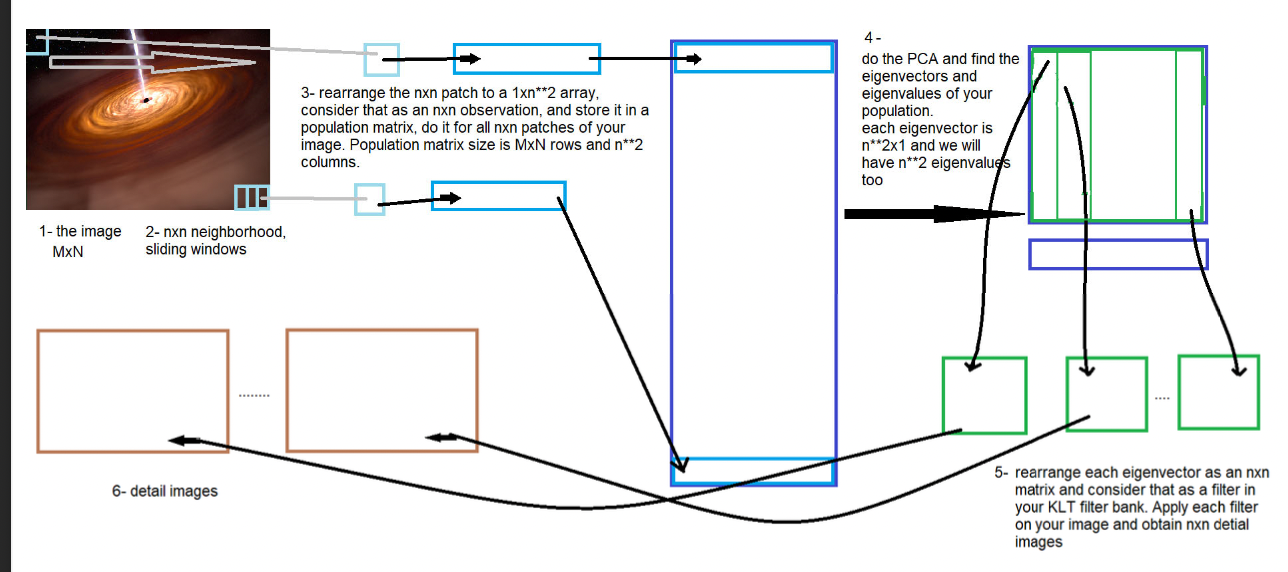
Karhonen‐Loeve Transform
Using nn sliding windows, nn local neighbourhoods of the image can be extracted and rearranged as different observations of data into a k*n**2 matrix (k is the number of sliding windows). Neighborhood size is typically
The covariance matrix is then computed, and the eigenvalues and eigenvectors of that population matrix are obtained:
A nn rearrangement of the eigenvectors could be interpreted as a bank of adapted filters of the same size, which optimally cover all nn relations of the test image pixels.
Detail images can be ontained by 2D spatial domain convolution of the test image by the members of the eigenfilter bank:
Then, to extract the feature vector, a few statistics of each detail image would be computed and used.
Ring/Wedge Filters
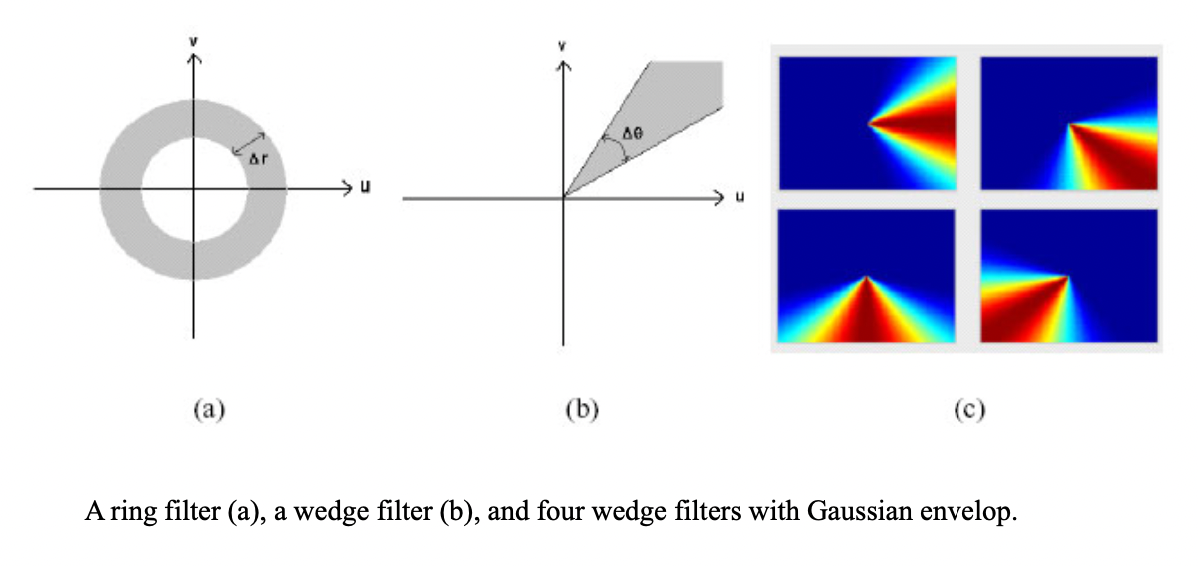
Wedge filter can etract info about edge in perpendicular direction in spatial domain. (e.g. vertical line for (c-1))
MSMD - Wavelet
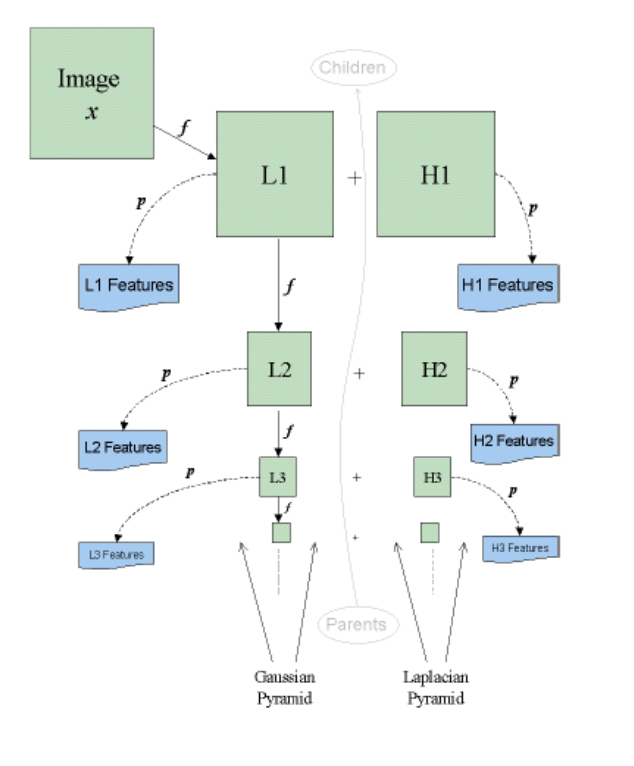
L1 + H1 = Image

Gaussian (a) and Laplacian(b) detail of an img

Filters employed for wavelet feature extraction
MSMD - Gabor filtering
12 filters

Intersection of a ring filter and a wedge filter in frequency domain
ANN and Deep Learning
Overfitting
Degree of freedom , number of constraints . To avoid loss of denerality in the system, must be times more than , →
In a NN, is the number of training examples,, and is the number of amendable parameters (mostly weights and biases)
Generative adversarial network
The generator’s objective is to model or generate data that is very similar to the training data.
The adversarial stage tries to classify input data; that is, given the features of an instance of data, they predict a label or category to which that data belongs.
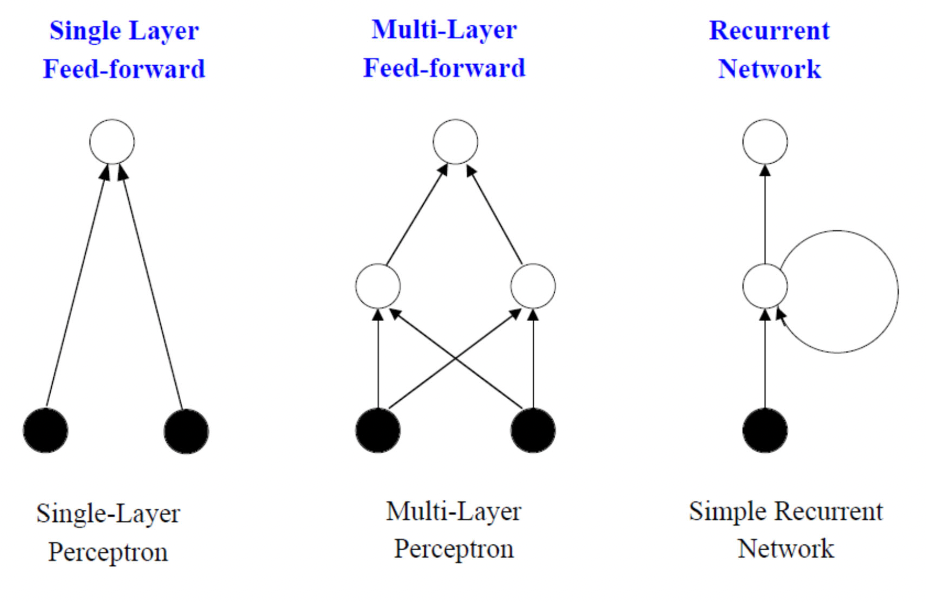
Recurrent Neural Network
A class of artificial neural networks where connections between nodes form a directed or undirected graph along a temporal sequence. This allows it to exhibit temporal dynamic behavior.
Can use their internal state (memory) to process variable‐length sequences of inuts.
LSTM and GRU
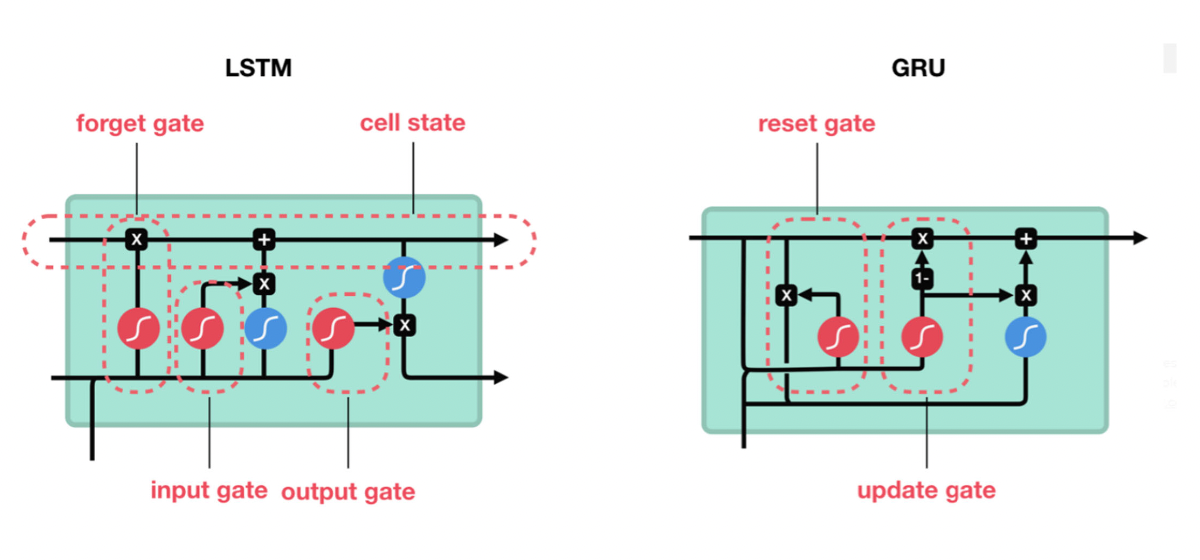
LSTM (Long short term memory) and GRU (Gated recurrent unit) have gates as internal mechanism, which control what info to keep and what info to throw out. By doing this, LSTM and GRU networks solve the exploding or vanishing gradient problem. These gates can learn which data in a sequence is important to keep or throw away.